To restart my career as a technical writer, I chose a light topic. Namely, running applications compiled with new versions of Visual Studio on Windows XP. I didn’t find any prior research on the topic, but I also didn’t search much. There’s no real purpose behind this article, beyond the fact that I wanted to know what could prevent a new application to run on XP. Our target application will be the embedded version of Python 3.7 for x86.
If we try to start any new application on XP, we’ll get an error message informing us that it is not a valid Win32 application. This happens because of some fields in the Optional Header of the Portable Executable.
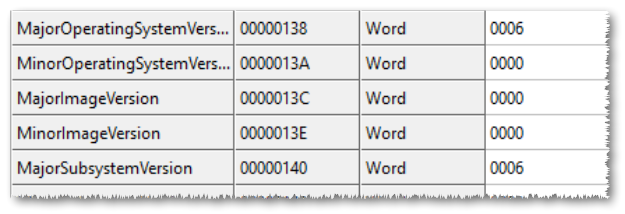
Most of you probably already know that you need to adjust these fields as follows:
MajorOperatingSystemVersion: 5
MinorOperatingSystemVersion: 0
MajorSubsystemVersion: 5
MinorSubsystemVersion: 0
Fortunately, it’s enough to adjust the fields in the executable we want to start (python.exe), there’s no need to adjust the DLLs as well.
If we try run the application now, we’ll get an error message due to a missing API in kernel32. So let’s turn our attention to the imports.
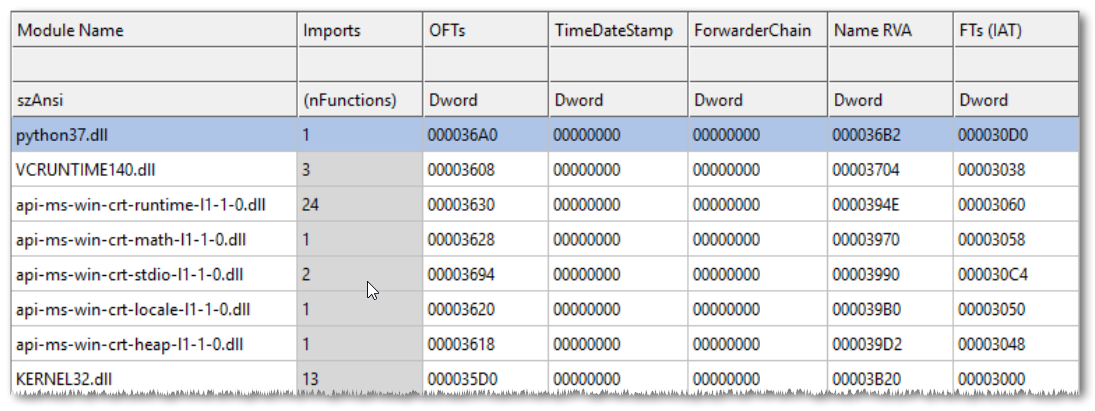
We have a missing vcruntime140.dll, then a bunch of “api-ms-win-*” DLLs, then only python37.dll and kernel32.dll.
The first thing which comes to mind is that in new applications we often find these “api-ms-win-*” DLLs. If we search for the prefix in the Windows directory, we’ll find a directory both in System32 and SysWOW64 called “downlevel”, which contains a huge list of these DLLs.
As we’ll see later, these DLLs aren’t actually used, but if we open one with a PE viewer, we’ll see that it contains exclusively forwarders to APIs contained in the usual suspects such as kernel32, kernelbase, user32 etc.
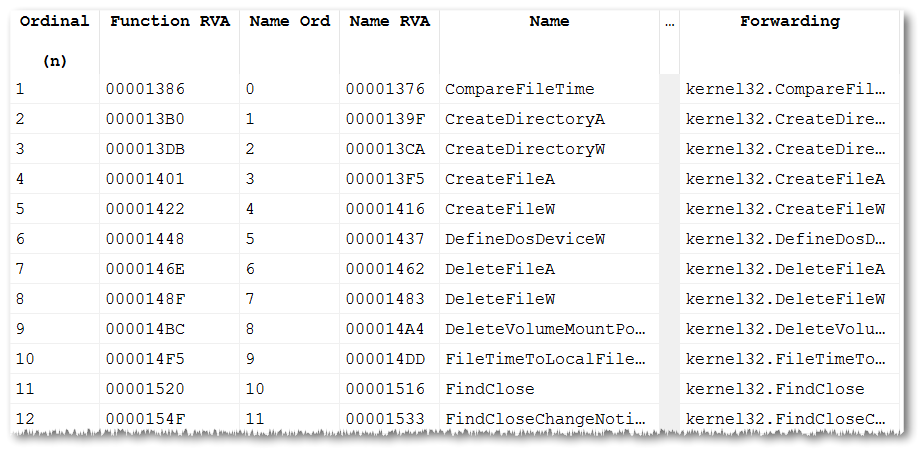
There’s a MSDN page documenting these DLLs.
Interestingly, in the downlevel directory we can’t find any of the files imported by python.exe. These DLLs actually expose C runtime APIs like strlen, fopen, exit and so on.
If we don’t have any prior knowledge on the topic and just do a string search inside the Windows directory for such a DLL name, we’ll find a match in C:\Windows\System32\apisetschema.dll. This DLL is special as it contains a .apiset section, whose data can easily be identified as some sort of format for mapping “api-ms-win-*” names to others.
Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F Ascii
00013AC0 C8 3A 01 00 20 00 00 00 73 00 74 00 6F 00 72 00 .:......s.t.o.r.
00013AD0 61 00 67 00 65 00 75 00 73 00 61 00 67 00 65 00 a.g.e.u.s.a.g.e.
00013AE0 2E 00 64 00 6C 00 6C 00 65 00 78 00 74 00 2D 00 ..d.l.l.e.x.t.-.
00013AF0 6D 00 73 00 2D 00 77 00 69 00 6E 00 2D 00 73 00 m.s.-.w.i.n.-.s.
00013B00 78 00 73 00 2D 00 6F 00 6C 00 65 00 61 00 75 00 x.s.-.o.l.e.a.u.
00013B10 74 00 6F 00 6D 00 61 00 74 00 69 00 6F 00 6E 00 t.o.m.a.t.i.o.n.
00013B20 2D 00 6C 00 31 00 2D 00 31 00 2D 00 30 00 00 00 -.l.1.-.1.-.0...
00013B30 00 00 00 00 00 00 00 00 00 00 00 00 44 3B 01 00 ............D;..
00013B40 0E 00 00 00 73 00 78 00 73 00 2E 00 64 00 6C 00 ....s.x.s...d.l.
00013B50 6C 00 00 00 65 00 78 00 74 00 2D 00 6D 00 73 00 l...e.x.t.-.m.s.
Searching on the web, the first resource I found on this topic were two articles on the blog of Quarkslab (Part 1 and Part 2). However, I quickly figured that, while useful, they were too dated to provide me with up-to-date structures to parse the data. In fact, the second article shows a version number of 2 and at the time of my writing the version number is 6.
Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F Ascii
00000000 06 00 00 00 ....
Just for completeness, after the publication of the current article, I was made aware of an article by deroko about the topic predating those of Quarkslab.
Anyway, I searched some more and found a code snippet by Alex Ionescu and Pavel Yosifovich in the repository of Windows Internals. I took the following structures from there.
typedef struct _API_SET_NAMESPACE {
ULONG Version;
ULONG Size;
ULONG Flags;
ULONG Count;
ULONG EntryOffset;
ULONG HashOffset;
ULONG HashFactor;
} API_SET_NAMESPACE, *PAPI_SET_NAMESPACE;
typedef struct _API_SET_HASH_ENTRY {
ULONG Hash;
ULONG Index;
} API_SET_HASH_ENTRY, *PAPI_SET_HASH_ENTRY;
typedef struct _API_SET_NAMESPACE_ENTRY {
ULONG Flags;
ULONG NameOffset;
ULONG NameLength;
ULONG HashedLength;
ULONG ValueOffset;
ULONG ValueCount;
} API_SET_NAMESPACE_ENTRY, *PAPI_SET_NAMESPACE_ENTRY;
typedef struct _API_SET_VALUE_ENTRY {
ULONG Flags;
ULONG NameOffset;
ULONG NameLength;
ULONG ValueOffset;
ULONG ValueLength;
} API_SET_VALUE_ENTRY, *PAPI_SET_VALUE_ENTRY; The data starts with a API_SET_NAMESPACE structure.
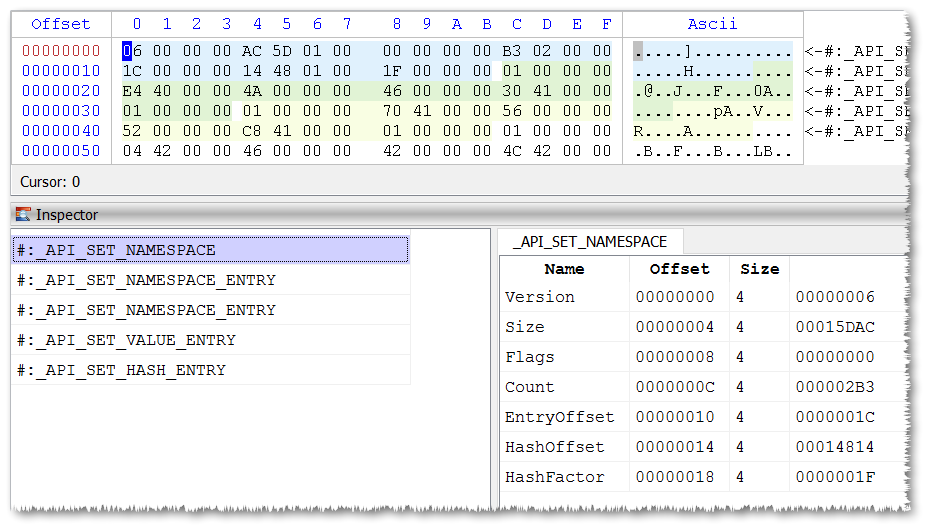
Count specifies the number of API_SET_NAMESPACE_ENTRY and API_SET_HASH_ENTRY structures. EntryOffset points to the start of the array of API_SET_NAMESPACE_ENTRY structures, which in our case comes exactly after API_SET_NAMESPACE.
Every API_SET_NAMESPACE_ENTRY points to the name of the “api-ms-win-*” DLL via the NameOffset field, while ValueOffset and ValueCount specify the position and count of API_SET_VALUE_ENTRY structures. The API_SET_VALUE_ENTRY structure yields the resolution values (e.g. kernel32.dll, kernelbase.dll) for the given “api-ms-win-*” DLL.
With this information we can already write a small script to map the new names to the actual DLLs.
import os
from Pro.Core import *
from Pro.PE import *
def main():
c = createContainerFromFile("C:\\Windows\\System32\\apisetschema.dll")
pe = PEObject()
if not pe.Load(c):
print("couldn't load apisetschema.dll")
return
sect = pe.SectionHeaders()
nsects = sect.Count()
d = None
for i in range(nsects):
if sect.Bytes(0) == b".apiset\x00":
cs = pe.SectionData(i)[0]
d = CFFObject()
d.Load(cs)
break
sect = sect.Add(1)
if not d:
print("could find .apiset section")
return
n, ret = d.ReadUInt32(12)
offs, ret = d.ReadUInt32(16)
for i in range(n):
name_offs, ret = d.ReadUInt32(offs + 4)
name_size, ret = d.ReadUInt32(offs + 8)
name = d.Read(name_offs, name_size).decode("utf-16")
line = str(i) + ") " + name + " ->"
values_offs, ret = d.ReadUInt32(offs + 16)
value_count, ret = d.ReadUInt32(offs + 20)
for j in range(value_count):
vname_offs, ret = d.ReadUInt32(values_offs + 12)
vname_size, ret = d.ReadUInt32(values_offs + 16)
vname = d.Read(vname_offs, vname_size).decode("utf-16")
line += " " + vname
values_offs += 20
offs += 24
print(line)
main() This code can be executed with Cerbero Profiler from command line as “cerpro.exe -r apisetschema.py”. These are the first lines of the produced output:
0) api-ms-onecoreuap-print-render-l1-1-0 -> printrenderapihost.dll
1) api-ms-onecoreuap-settingsync-status-l1-1-0 -> settingsynccore.dll
2) api-ms-win-appmodel-identity-l1-2-0 -> kernel.appcore.dll
3) api-ms-win-appmodel-runtime-internal-l1-1-3 -> kernel.appcore.dll
4) api-ms-win-appmodel-runtime-l1-1-2 -> kernel.appcore.dll
5) api-ms-win-appmodel-state-l1-1-2 -> kernel.appcore.dll
6) api-ms-win-appmodel-state-l1-2-0 -> kernel.appcore.dll
7) api-ms-win-appmodel-unlock-l1-1-0 -> kernel.appcore.dll
8) api-ms-win-base-bootconfig-l1-1-0 -> advapi32.dll
9) api-ms-win-base-util-l1-1-0 -> advapi32.dll
10) api-ms-win-composition-redirection-l1-1-0 -> dwmredir.dll
11) api-ms-win-composition-windowmanager-l1-1-0 -> udwm.dll
12) api-ms-win-core-apiquery-l1-1-0 -> ntdll.dll
13) api-ms-win-core-appcompat-l1-1-1 -> kernelbase.dll
14) api-ms-win-core-appinit-l1-1-0 -> kernel32.dll kernelbase.dll
...
Going back to API_SET_NAMESPACE, its field HashOffset points to an array of API_SET_HASH_ENTRY structures. These structures, as we’ll see in a moment, are used by the Windows loader to quickly index a “api-ms-win-*” DLL name. The Hash field is effectively the hash of the name, calculated by taking into consideration both HashFactor and HashedLength, while Index points to the associated API_SET_NAMESPACE_ENTRY entry.
The code which does the hashing is inside the function LdrpPreprocessDllName in ntdll:
77EA1DAC mov ebx, dword ptr [ebx + 0x18] ; HashFactor in ebx
77EA1DAF mov esi, eax ; esi = dll name length
77EA1DB1 movzx eax, word ptr [edx] ; one unicode character into eax
77EA1DB4 lea ecx, dword ptr [eax - 0x41] ; ecx = character - 0x41
77EA1DB7 cmp cx, 0x19 ; compare to 0x19
77EA1DBB jbe 0x77ea2392 ; if below or equal, bail out
77EA1DC1 mov ecx, ebx ; ecx = HashFactor
77EA1DC3 movzx eax, ax
77EA1DC6 imul ecx, edi ; ecx *= edi
77EA1DC9 add edx, 2 ; edx += 2
77EA1DCC add ecx, eax ; ecx += eax
77EA1DCE mov edi, ecx ; edi = ecx
77EA1DD0 sub esi, 1 ; len -= 1
77EA1DD3 jne 0x77ea1db1 ; if not zero repeat from 77EA1DB1
Or more simply in C code:
const char *p = dllname;
int HashedLength = 0x23;
int HashFactor = 0x1F;
int Hash = 0;
for (int i = 0; i < HashedLength; i++, p++)
Hash = (Hash * HashFactor) + *p; As a practical example, let's take the DLL name "api-ms-win-core-processthreads-l1-1-2.dll". Its hash would be 0x445B4DF3. If we find its matching API_SET_HASH_ENTRY entry, we'll have the Index to the associated API_SET_NAMESPACE_ENTRY structure.
Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F Ascii
00014DA0 F3 4D 5B 44 .M[D
00014DB0 5B 00 00 00 [...
So, 0x5b (or 91) is the index. By going back to the output of mappings, we can see that it matches.
91) api-ms-win-core-processthreads-l1-1-3 -> kernel32.dll kernelbase.dll
By inspecting the same output, we can also notice that all C runtime DLLs are resolved to ucrtbase.dll.
167) api-ms-win-crt-conio-l1-1-0 -> ucrtbase.dll
168) api-ms-win-crt-convert-l1-1-0 -> ucrtbase.dll
169) api-ms-win-crt-environment-l1-1-0 -> ucrtbase.dll
170) api-ms-win-crt-filesystem-l1-1-0 -> ucrtbase.dll
171) api-ms-win-crt-heap-l1-1-0 -> ucrtbase.dll
172) api-ms-win-crt-locale-l1-1-0 -> ucrtbase.dll
173) api-ms-win-crt-math-l1-1-0 -> ucrtbase.dll
174) api-ms-win-crt-multibyte-l1-1-0 -> ucrtbase.dll
175) api-ms-win-crt-private-l1-1-0 -> ucrtbase.dll
176) api-ms-win-crt-process-l1-1-0 -> ucrtbase.dll
177) api-ms-win-crt-runtime-l1-1-0 -> ucrtbase.dll
178) api-ms-win-crt-stdio-l1-1-0 -> ucrtbase.dll
179) api-ms-win-crt-string-l1-1-0 -> ucrtbase.dll
180) api-ms-win-crt-time-l1-1-0 -> ucrtbase.dll
181) api-ms-win-crt-utility-l1-1-0 -> ucrtbase.dll
I was already resigned at having to figure out how to support the C runtime on XP, when I noticed that Microsoft actually supports the deployment of the runtime on it. The following excerpt from MSDN says as much:
If you currently use the VCRedist (our redistributable package files), then things will just work for you as they did before. The Visual Studio 2015 VCRedist package includes the above mentioned Windows Update packages, so simply installing the VCRedist will install both the Visual C++ libraries and the Universal CRT. This is our recommended deployment mechanism. On Windows XP, for which there is no Universal CRT Windows Update MSU, the VCRedist will deploy the Universal CRT itself.
Which means that on Windows editions coming after XP the support is provided via Windows Update, but on XP we have to deploy the files ourselves. We can find the files to deploy inside C:\Program Files (x86)\Windows Kits\10\Redist\ucrt\DLLs. This path contains three sub-directories: x86, x64 and arm. We're obviously interested in the x86 one. The files contained in it are many (42), apparently the most common "api-ms-win-*" DLLs and ucrtbase.dll. We can deploy those files onto XP to make our application work. We are still missing the vcruntime140.dll, but we can take that DLL from the Visual C++ installation. In fact, that DLL is intended to be deployed, while the Universal CRT (ucrtbase.dll) is intended to be part of the Windows system.
This satisfies our dependencies in terms of DLLs. However, Windows introduced many new APIs over the years which aren't present on XP. So I wrote a script to test the compatibility of an application by checking the imported APIs against the API exported by the DLLs on XP. The command line for it is "cerpro.exe -r xpcompat.py application_path". It will check all the PE files in the specified directory.
import os, sys
from Pro.Core import *
from Pro.PE import *
xp_system32 = "C:\\Users\\Admin\\Desktop\\system32"
apisetschema = { "OMITTED FOR BREVITY" }
cached_apis = {}
missing_result = {}
def getAPIs(dllpath):
apis = {}
c = createContainerFromFile(dllpath)
dll = PEObject()
if not dll.Load(c):
print("error: couldn't load dll")
return apis
ordbase = dll.ExportDirectory().Num("Base")
functions = dll.ExportDirectoryFunctions()
names = dll.ExportDirectoryNames()
nameords = dll.ExportDirectoryNameOrdinals()
n = functions.Count()
it = functions.iterator()
for x in range(n):
func = it.next()
ep = func.Num(0)
if ep == 0:
continue
apiord = str(ordbase + x)
n2 = nameords.Count()
it2 = nameords.iterator()
name_found = False
for y in range(n2):
no = it2.next()
if no.Num(0) == x:
name = names.At(y)
offs = dll.RvaToOffset(name.Num(0))
name, ret = dll.ReadUInt8String(offs, 500)
apiname = name.decode("ascii")
apis[apiname] = apiord
apis[apiord] = apiname
name_found = True
break
if not name_found:
apis[apiord] = apiord
return apis
def checkMissingAPIs(pe, ndescr, dllname, xpdll_apis):
ordfl = pe.ImportOrdinalFlag()
ofts = pe.ImportThunks(ndescr)
it = ofts.iterator()
while it.hasNext():
ft = it.next().Num(0)
if (ft & ordfl) != 0:
name = str(ft ^ ordfl)
else:
offs = pe.RvaToOffset(ft)
name, ret = pe.ReadUInt8String(offs + 2, 400)
if not ret:
continue
name = name.decode("ascii")
if not name in xpdll_apis:
print(" ", "missing:", name)
temp = missing_result.get(dllname, set())
temp.add(name)
missing_result[dllname] = temp
def verifyXPCompatibility(fname):
print("file:", fname)
c = createContainerFromFile(fname)
pe = PEObject()
if not pe.Load(c):
return
it = pe.ImportDescriptors().iterator()
ndescr = -1
while it.hasNext():
descr = it.next()
ndescr += 1
offs = pe.RvaToOffset(descr.Num("Name"))
name, ret = pe.ReadUInt8String(offs, 400)
if not ret:
continue
name = name.decode("ascii").lower()
if not name.endswith(".dll"):
continue
fwdlls = apisetschema.get(name[:-4], [])
if len(fwdlls) == 0:
print(" ", name)
else:
fwdll = fwdlls[0]
print(" ", name, "->", fwdll)
name = fwdll
if name == "ucrtbase.dll":
continue
xpdll_path = os.path.join(xp_system32, name)
if not os.path.isfile(xpdll_path):
continue
if not name in cached_apis:
cached_apis[name] = getAPIs(xpdll_path)
checkMissingAPIs(pe, ndescr, name, cached_apis[name])
print()
def main():
if os.path.isfile(sys.argv[1]):
verifyXPCompatibility(sys.argv[1])
else:
files = [os.path.join(dp, f) for dp, dn, fn in os.walk(sys.argv[1]) for f in fn]
for fname in files:
with open(fname, "rb") as f:
if f.read(2) == b"MZ":
verifyXPCompatibility(fname)
# summary
n = 0
print("\nsummary:")
for rdll, rapis in missing_result.items():
print(" ", rdll)
for rapi in rapis:
print(" ", "missing:", rapi)
n += 1
print("total of missing APIs:", str(n))
main() I had to omit the contents of the apisetschema global variable for the sake of brevity. You can download the full script from here. The system32 directory referenced in the code is the one of Windows XP, which I copied to my desktop.
And here are the relevant excerpts from the output:
file: python-3.7.0-embed-win32\python37.dll
version.dll
shlwapi.dll
ws2_32.dll
kernel32.dll
missing: GetFinalPathNameByHandleW
missing: InitializeProcThreadAttributeList
missing: UpdateProcThreadAttribute
missing: DeleteProcThreadAttributeList
missing: GetTickCount64
advapi32.dll
vcruntime140.dll
api-ms-win-crt-runtime-l1-1-0.dll -> ucrtbase.dll
api-ms-win-crt-math-l1-1-0.dll -> ucrtbase.dll
api-ms-win-crt-locale-l1-1-0.dll -> ucrtbase.dll
api-ms-win-crt-string-l1-1-0.dll -> ucrtbase.dll
api-ms-win-crt-stdio-l1-1-0.dll -> ucrtbase.dll
api-ms-win-crt-convert-l1-1-0.dll -> ucrtbase.dll
api-ms-win-crt-time-l1-1-0.dll -> ucrtbase.dll
api-ms-win-crt-environment-l1-1-0.dll -> ucrtbase.dll
api-ms-win-crt-process-l1-1-0.dll -> ucrtbase.dll
api-ms-win-crt-heap-l1-1-0.dll -> ucrtbase.dll
api-ms-win-crt-conio-l1-1-0.dll -> ucrtbase.dll
api-ms-win-crt-filesystem-l1-1-0.dll -> ucrtbase.dll
[...]
file: python-3.7.0-embed-win32\_socket.pyd
ws2_32.dll
missing: inet_ntop
missing: inet_pton
kernel32.dll
python37.dll
vcruntime140.dll
api-ms-win-crt-runtime-l1-1-0.dll -> ucrtbase.dll
[...]
summary:
kernel32.dll
missing: InitializeProcThreadAttributeList
missing: GetTickCount64
missing: GetFinalPathNameByHandleW
missing: UpdateProcThreadAttribute
missing: DeleteProcThreadAttributeList
ws2_32.dll
missing: inet_pton
missing: inet_ntop
total of missing APIs: 7 We're missing 5 APIs from kernel32.dll and 2 from ws2_32.dll, but the Winsock APIs are imported just by _socket.pyd, a module which is loaded only when a network operation is performed by Python. So, in theory, we can focus our efforts on the missing kernel32 APIs for now.
My plan was to create a fake kernel32.dll, called xernel32.dll, containing forwarders for most APIs and real implementations only for the missing ones. Here's a script to create C++ files containing forwarders for all APIs of common DLLs on Windows 10:
import os, sys
from Pro.Core import *
from Pro.PE import *
xpsys32path = "C:\\Users\\Admin\\Desktop\\system32"
sys32path = "C:\\Windows\\SysWOW64"
def getAPIs(dllpath):
pass # same code as above
def isOrdinal(i):
try:
int(i)
return True
except:
return False
def createShadowDll(name):
xpdllpath = os.path.join(xpsys32path, name + ".dll")
xpapis = getAPIs(xpdllpath)
dllpath = os.path.join(sys32path, name + ".dll")
apis = sorted(getAPIs(dllpath).keys())
if len(apis) != 0:
with open(name + ".cpp", "w") as f:
f.write("#include \n\n")
for a in apis:
comment = " // XP" if a in xpapis else ""
if not isOrdinal(a):
f.write("#pragma comment(linker, \"/export:" + a + "=" + name + "." + a + "\")" + comment + "\n")
#
print("created", name + ".cpp")
def main():
dlls = ("advapi32", "comdlg32", "gdi32", "iphlpapi", "kernel32", "ole32", "oleaut32", "shell32", "shlwapi", "user32", "uxtheme", "ws2_32")
for dll in dlls:
createShadowDll(dll)
main() It creates files like the following kernel32.cpp:
#include
#pragma comment(linker, "/export:AcquireSRWLockExclusive=kernel32.AcquireSRWLockExclusive")
#pragma comment(linker, "/export:AcquireSRWLockShared=kernel32.AcquireSRWLockShared")
#pragma comment(linker, "/export:ActivateActCtx=kernel32.ActivateActCtx") // XP
#pragma comment(linker, "/export:ActivateActCtxWorker=kernel32.ActivateActCtxWorker")
#pragma comment(linker, "/export:AddAtomA=kernel32.AddAtomA") // XP
#pragma comment(linker, "/export:AddAtomW=kernel32.AddAtomW") // XP
#pragma comment(linker, "/export:AddConsoleAliasA=kernel32.AddConsoleAliasA") // XP
#pragma comment(linker, "/export:AddConsoleAliasW=kernel32.AddConsoleAliasW") // XP
#pragma comment(linker, "/export:AddDllDirectory=kernel32.AddDllDirectory")
[...]
The comment on the right ("// XP") indicates whether the forwarded API is present on XP or not. We can provide real implementations exclusively for the APIs we want. The Windows loader doesn't care whether we forward functions which don't exist as long as they aren't imported.
The APIs we need to support are the following:
GetTickCount64: I just called GetTickCount, not really important
GetFinalPathNameByHandleW: took the implementation from Wine, but had to adapt it slightly
InitializeProcThreadAttributeList: took the implementation from Wine
UpdateProcThreadAttribute: same
DeleteProcThreadAttributeList: same
I have to be grateful to the Wine project here, as it provided useful implementations, which saved me the effort.
I called the attempt at a support runtime for older Windows versions "XP Time Machine Runtime" and you can find the repository here. I compiled it with Visual Studio 2013 and cmake.
So that we have now our xernel32.dll, the only thing we have to do is to rename the imported DLL inside python37.dll.
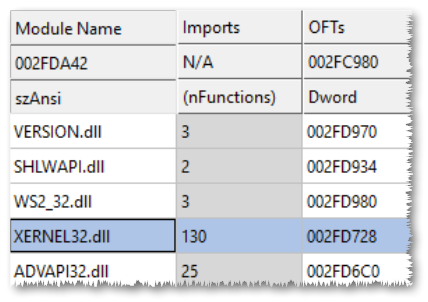
Let's try to start python.exe.
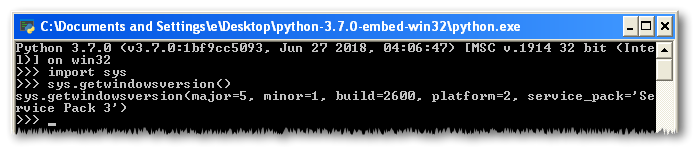
Awesome.
Of course, we're still not completely done, as we didn't implement the missing Winsock APIs, but perhaps this and some more could be the content of a second part to this article.