.NET Internals and Native Compiling
This article is the second of a two series of articles about the .NET Framework internals and the protections available for .NET assemblies. This article analyzes more in depth the .NET internals. Thus, the reader should be familiar with the past article, otherwise certain paragraphs of this article may seem obscure. As the JIT inner workings haven't been analyzed yet, .NET protections are quite naďve nowadays. This situation will rapidly change as soon as the reverse engineering community will focus its attention on this technology. These two articles are aimed to raise the consciousness about the current state of .NET protections and what is possible to achieve but hasn't been done yet. In particular, the past article about .NET code injection represents, let's say, the present, whereas the current one about .NET native compiling represents the future. What I'm presenting in these two articles is new at the time I'm writing it, but I expect it to become obsolete in less than a year. Of course, this is obvious as I'm moving the first steps out from current .NET protections in the direction of better ones. But this article isn't really about protections: exploring the .NET Framework internals can be useful for many purposes. So, talking about protections is just a means to an end.
Strictly speaking it means converting the MSIL code of a .NET assembly to native machine code and then removing the MSIL code from that assembly, making it impossible to decompile it in a straightforward way. The only existing tool to native compile .NET assemblies is the Salamander.NET linker which relies on native images to do its job. The "native images" (which in this article I called "Native Framework Deployment") technique is quite distant from .NET internals: one doesn't need a good knowledge of .NET internals to implement it. But, as the topic is, I might say, quite popular, I'm going to show to the reader how to write his Native Framework Deployment tool if he wishes to. However, the article will go further than that by introducing Native Injection, which means nothing else than taking the JIT's place. Even though this is not useful for commercial protections (or whatever), it's a good way to play with JIT internals. I'm also going to introduce Native Decompiling, which is the result of an understanding of .NET internals. I'm also trying to address another topic: .NET Virtual Machine Protections.
The internal format of native images is yet undocumented. It also would be quite hard documenting it as it constantly changes. For instance, it completely changed from version 1 to version 2 of the .NET framework. And, as the new framework 3.5 SP1 has been released a few days ago, it changed another time. I'm not sure on what extent it changed in the last version, but one change can be noticed immediately. The original MetaData is now directly available without changing the entry in the .NET directory to the MetaData RVA found in the Native Header. If you do that action, you'll end up with the native image MetaData which isn't much interesting. Also, in earlier native images (previous to 3.5 SP1 framework) to obtain the original MSIL code of a method, one had to add the RVA found in the MethodDef table to the Original MSIL Code RVA entry in the native header. This is no longer necessary as the MethodDef RVA entry now points directly to the method's MSIL code.
This is important, since protections like the Salamander Linker need to remove the original MSIL code from a native image before they can deploy it. Otherwise the whole protection become useless, since MetaData and MSIL code are all what is necessary to rebuild a fully decompilable .NET assembly. The stripping of MSIL code was easier in the "old" format, because one only needed the Original MSIL Code RVA and Size entries to know which part of the native image had to be erased with a simple memset.
All we need to know about the native images' format in order to write a Native Framework Deployment tool is how to strip the MSIL code from it. Even the Salamander Linker will need time to adapt to the new native image format in order to work with the framework 3.5 SP1. And, as there isn't currently any protection which works with 3.5 SP1 native images, what I'm writing in this article has been only tested against earlier images.
Another reason why it is difficult to document native images is the lack of the code which handles them in the Rotor project. It was a deliberate choice made by Microsoft to exclude this part of the framework from the Rotor project.
The name I gave to this sort of protection may appear a bit strange, but it will appear quite obvious as soon as I have explained how it actually works. As already said, there's no protection system other than the Salamander Linker which removes the MSIL and ships only native machine code. And, in order to do that, the Salamander Linker relies on native images generated by ngen. The Salamander Linker offers a downloadable demonstration on its home page and we will take a look at that without, of course, analyzing its code, as I don't intend to violate any licensing terms it may imply. In this paragraph I'm going to show how it is technically quite easy to write a Native Framework Deployment tool, but I doubt that the reader will want to write one after reading this. Don't get me wrong, the Salamander Linker absolutely holds its promise and actually removes the MSIL code from one's application, but the method used faces many problems and in my opinion is not a real solution.
The Salamander Linker's demonstration is called scribble and it's a simple MDI application. Let's look at the application's main directory:
The v2.0.50727 directory corresponds to the framework directory which can be found inside "C:\Windows\Microsoft.NET\", although it comes with only a limited number of files inside:
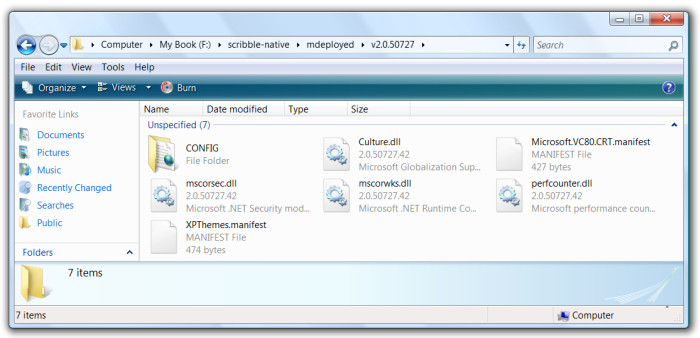
I'll explain in a moment why some important assemblies like System or System.Windows.Forms are missing. Meanwhile, the "C" directory leads to a series of other directories. The main path it produces looks something like this: "C\WINDOWS\assembly\". In the last directory of this path two more directories are contained. One directory is called "GAC_32" and contains the mscorlib assembly. The other directory is called "NativeImages_v2.0.50727_32" and is the directory where native images are stored. This directory contains only two native images: the mscorlib one and the scribble one. The scribble native image is gigantic, that's because before ngening scribble was merged with its dependencies: System, System.Windows.Forms, etc. The only dependency which can't be merged to another assembly is mscorlib. The reasons for that are many. The reader can imagine one of them if he has read the past article: mscorlib is a low level assembly strictly connected to the framework, among the things it does it provides the internal calls implementation. If a non-system assembly tries to call an internal function, it will only result in the framework displaying a privileges error.
The Salamander Linker deploys a subset of the framework. Thus, the name Native Framework Deployment I gave to this technique. Native images are bound to a the framework in a rather complicate way. In fact, native images are highly framework dependent. But let's for a second focus only on the relationship between an assembly and its native image on the local system. One can modify an assembly all he wants, but by just leaving its #GUID stream and some data in the MetaData table unchanged the same native image will be loaded for that assembly. This means that one can even bind a totally different assembly to a native image. This is quite easy to achieve: first, let's ngen a random assembly. Assemblies are bound to their native images through the registry. The registry key "HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Fusion\NativeImagesIndex\v2.0.50727_32" is where the binding between assemblies and native images happens:
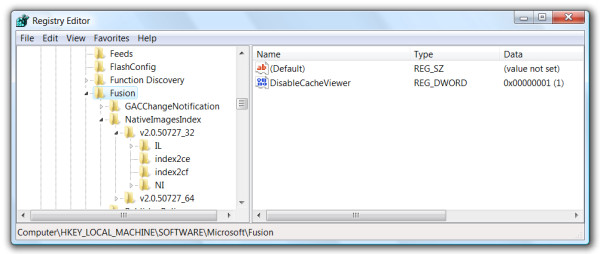
This key has two subkeys: "IL" and "NI". The "IL" key contains a series of subkeys which represent the ngened assemblies and the information needed to bind them to their native images:
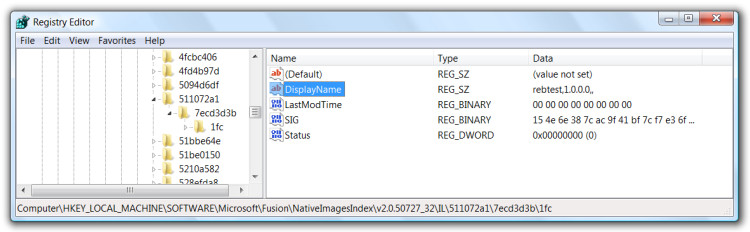
Keep in mind the DisplayName as it The SIG value contains the assembly's GUID and its SHA1 hash:
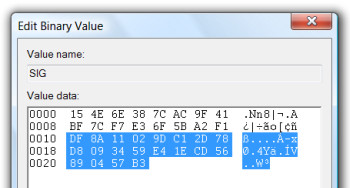
The selected bytes represent the SHA1 hash. Ironically, this hash isn't used to bind the actual assembly to its native image. But this behaviour might change in the future, so it's worth mentioning.
The "NI" key's subkeys tell the framework where it can find the native image for a given assembly:
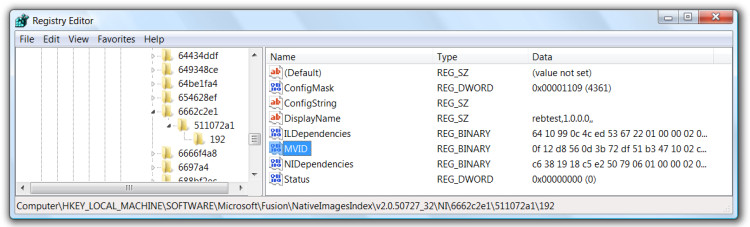
The MVID value specifies the path of the native image. In this case it'll be: "C:\Windows\assembly\NativeImages_v2.0.50727_32\rebtest\0f12d8560d3b72df51b3471002c911a0". Also, it should be noted that the "511072a1" subkey references the appropriate "IL" subkey.
So, in order to bind another assembly to this assembly's native image, it is necessary to change its GUID and also the Assembly MetaData table:
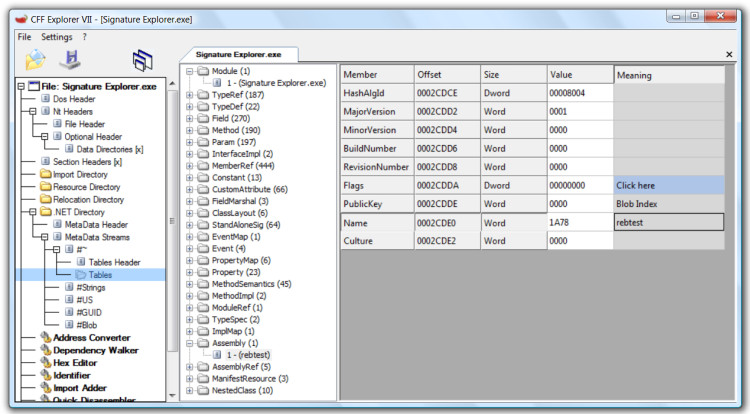
The Name in the Assembly MetaData table should be changed to the display name (in this case: "rebtest"). Also, change the MajorVersion, MinorVersion, BuildNumber and RevisionNumber accordingly. I showed the Module Table in the image just because it would be logical to change that as well, but the framework doesn't care about it. Thus, neither do we.
This is all it takes to bind a local image and it works with the framework 3.5 SP1 as well. Of course, binding a native image on another computer isn't as easy, since native images are framework / system dependent. And also it is not guaranted to work, since, as mentioned earlier, native images may change along with newer versions of the framework. This problem can be "solved" by shipping the whole framework along with the native images.
Let's go back to the Salamander Linker demonstation's main directory. The "Scribble.exe" is a native exe which loads the "Scribble.rsm". "Scribble.rsm" is an empty assembly used to load a native image. The binding between this empty assembly and a native image is done how I described above. By shipping its own framework version the Salamander Linker has only to worry about local binding. Of course, it is not sufficient to put the framework files in a folder in order to deploy it. A virtualization has to be provided as well. The "mdepoy.registry" is a text file which contains the registry keys to virtualize. It looks like this:
|
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Fusion\NativeImagesIndex\v2.0.50727_32\IL] [HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Fusion\NativeImagesIndex\v2.0.50727_32\IL\23ca0da0] [HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Fusion\NativeImagesIndex\v2.0.50727_32\IL\23ca0da0\2bbf7a73] [HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Fusion\NativeImagesIndex\v2.0.50727_32\IL\23ca0da0\2bbf7a73\8] "DisplayName"="Scribble,0.0.0.0,," "SIG"=hex:af,ab,74,2d,d3,3a,1c,43,be,55,fc,b4,11,39,af,45,b7,ce,d1,a1,22,41,42,\ 18,11,62,fb,d2,01,d5,41,f6,24,46,e2,15 "Status"=dword:00000000 "LastModTime"=hex:00,00,00,00,00,00,00,00 |
The actual file is much bigger (31 kb). "rsdeploy.dll" is the part of the Salamander Linker which does most of the work: it hooks all the APIs it needs to virtualize the framework. This can be easily verified without analyzing its code. Among the APIs it needs to hook there's LoadLibrary, of course, and all registry functions. It also needs to hook some other functions, which I'm going to discuss in the next paragraph.
When virtualizing an application there's not only the file system and the registry to consider. Environment variables have to be considered as well. If we look at the environment of the Scribble process with Russinovich's Process Explorer we will notice something:
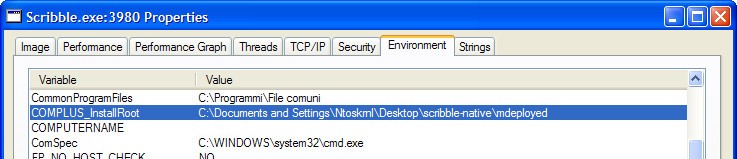
The Salamander Linker sets the COMPLUS_InstallRoot variable to its own main directory. Since this variable is not used and the framework is loaded even without it, my guess is that it's a deprecated variable of the framework 1.0.
This is about everything one has to know in order to develop his own Native Framework Deployment tool. One might be asking where the merging part comes in. Actually, the merging is not really necessary. It only makes things easier and also, since the whole framework is shipped, it speeds up performances. I could easily adapt the Rebel.NET code to write an assembly merger (it would be a two-weeks job), but I'm not interested in anything that can be achieved through merging assemblies: like, for instance, writing a protection like this one. As alternative, one might consider using ILMerge, a Microsoft utility which can also be used in commercial applications. The only drawback is that it is extremely slow (it's a .NET assembly) and I have already experienced cases where it doesn't work, but this may improve in time. In the next sub-paragraphs I'm going to address some aspects of the possible development of a Native Framework Deployment service.
Let's see how a possible loader for a Native Framework Deployment service may look like. What follows is only a first draft of the loader: I'm not introducing the complete loader yet, because I'm proceeding gradually.
| int APIENTRY _tWinMain(HINSTANCE
hInstance, HINSTANCE hPrevInstance, LPTSTR lpCmdLine, int nCmdShow) { // // set COMPLUS_InstallRoot environment variable // (useless on framework 2.0 and later) // /* TCHAR CurPath[MAX_PATH]; GetModuleFileName(NULL, CurPath, MAX_PATH); TCHAR *pSlash = _tcsrchr(CurPath, '\\'); if (pSlash) *pSlash = 0; SetEnvironmentVariable(_T("COMPLUS_InstallRoot"), CurPath); */ ////////////////////////////////////////////////////////////////////////// // TODO: hook registry APIs, LoadLibrary and ... ////////////////////////////////////////////////////////////////////////// HMODULE hMainAsm = LoadLibrary(ASSEMBLY_TO_LOAD); if (hMainAsm == NULL) return 0; IMAGE_DOS_HEADER *pDosHeader = (IMAGE_DOS_HEADER *) hMainAsm; IMAGE_NT_HEADERS *pNtHeaders = (IMAGE_NT_HEADERS *) (pDosHeader->e_lfanew + (ULONG_PTR) pDosHeader); if (pNtHeaders->OptionalHeader.ImageBase != (ULONG_PTR) pDosHeader) FixReloc(pDosHeader, pNtHeaders); FixIAT(pDosHeader, pNtHeaders); // retrieve entry point VOID *pEntryPoint = (VOID *) (pNtHeaders->OptionalHeader.AddressOfEntryPoint + (ULONG_PTR) pDosHeader); __asm jmp pEntryPoint; return 0; } |
There are a few things to say about this code. For once, it may not seem
obvious to the reader why I'm fixing IAT and relocations. Usually, LoadLibrary
(which I'm using to load the assembly) does this task, but on systems which have
the .NET framework installed it doesn't do this for .NET assemblies.
After fixing the PE, I jump to the assembly's entry point (which is just a jump
to _CorExeMain in mscoree). Actually, I could have called the _CorExeMain
directly without jumping to the original entry point. Thus, making the code to
fix IAT and relocations not necessary. I just did it this way in order to avoid
any incompatibilities in the future. The key point to load an assembly is to
understand how _CorExeMain is going to retrieve the base address of the main
assembly in the current address space. The code of _CorExeMain, after doing some
checks to load the correct .NET runtime, calls the same function inside mscorwks. Here's the
ide mscorwks. Here's the
code inside mscorwks:
.text:79F05ECA ; int __stdcall _CorExeMain()
.text:79F05ECA public __CorExeMain@0
.text:79F05ECA __CorExeMain@0 proc near
.text:79F05ECA
.text:79F05ECA var_2C = byte ptr -2Ch
.text:79F05ECA var_28 = dword ptr -28h
.text:79F05ECA var_1C = byte ptr -1Ch
.text:79F05ECA var_18 = dword ptr -18h
.text:79F05ECA var_14 = dword ptr -14h
.text:79F05ECA var_4 = dword ptr -4
.text:79F05ECA
.text:79F05ECA ; FUNCTION CHUNK AT .text:79FBF47D SIZE 0000005A BYTES
.text:79F05ECA ; FUNCTION CHUNK AT .text:79FBF4FC SIZE 00000042 BYTES
.text:79F05E push 20h
.text:79F05ECC mov eax, offset loc_7A2EE124
.text:79F05ED1 call __EH_prolog3_catch
.text:79F05ED6 xor edi, edi
.text:79F05ED8 push edi ; lpModuleName
.text:79F05ED9 call ?WszGetModuleHandle@@YGPAUHINSTANCE__@@PBG@Z ; WszGetModuleHandle(ushort const *)
The _CorExeMain function in mscorwks retrieves the main assembly through a call to GetModuleHandleA/W(NULL) called inside WszGetModuleHandle. Not only that: before GetModuleHandle, GetModuleFileName gets called inside mscoree. This API accepts the same NULL syntax as GetModuleHandle to obtain information about the main module in the current address space. So, the easiest way to tell the framework which the main assembly is, is to hook both GetModuleHandleA/W and GetModuleFileNameA/W. I decided to use Microsoft's Detour to implement the hooking, since its licensing is free for research projects and it is guaranted to work on every Windows platform. Here's the code of the actual loader:
| #include "stdafx.h" #include "fxloader.h" #include "detours.h" #define ASSEMBLY_TO_LOAD _T("rebtest.exe") #define ASSEMBLY_TO_LOAD_A "rebtest.exe" #define ASSEMBLY_TO_LOAD_W L"rebtest.exe" #define IS_FLAG(Value, Flag) ((Value & Flag) == Flag) typedef ULONG_PTR THUNK; VOID FixIAT(VOID *pBase, IMAGE_NT_HEADERS *pNtHeaders); VOID FixReloc(VOID *pBase, IMAGE_NT_HEADERS *pNtHeaders); HMODULE pMainBaseAddr = NULL; CHAR MainAsmNameA[MAX_PATH]; WCHAR MainAsmNameW[MAX_PATH]; HMODULE (WINAPI *pGetModuleHandleA)(LPCSTR lpModuleName) = GetModuleHandleA; HMODULE (WINAPI *pGetModuleHandleW)(LPCWSTR lpModuleName) = GetModuleHandleW; DWORD (WINAPI *pGetModuleFileNameA)(HMODULE hModule, LPCH lpFilename, DWORD nSize) = GetModuleFileNameA; DWORD (WINAPI *pGetModuleFileNameW)(HMODULE hModule, LPWCH lpFilename, DWORD nSize) = GetModuleFileNameW; HMODULE WINAPI MyGetModuleHandleA(LPCSTR lpModuleName); HMODULE WINAPI MyGetModuleHandleW(LPCWSTR lpModuleName); DWORD WINAPI MyGetModuleFileNameA(HMODULE hModule, LPCH lpFilename, DWORD nSize); DWORD WINAPI MyGetModuleFileNameW(HMODULE hModule, LPWCH lpFilename, DWORD nSize); int APIENTRY _tWinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPTSTR lpCmdLine, int nCmdShow) { ////////////////////////////////////////////////////////////////////////// // TODO: hook registry and load library ////////////////////////////////////////////////////////////////////////// HMODULE hMainAsm = LoadLibrary(ASSEMBLY_TO_LOAD); if (hMainAsm == NULL) return 0; pMainBaseAddr = hMainAsm; GetModuleFileNameA(NULL, MainAsmNameA, MAX_PATH); CHAR *cSlash = strrchr(MainAsmNameA, '\\') + 1; strcpy(cSlash, ASSEMBLY_TO_LOAD_A); GetModuleFileNameW(NULL, MainAsmNameW, MAX_PATH); WCHAR *wSlash = wcsrchr(MainAsmNameW, '\\') + 1; wcscpy(wSlash, ASSEMBLY_TO_LOAD_W); // // Hook GetModuleXXXX APIs // DetourRestoreAfterWith(); DetourTransactionBegin(); DetourUpdateThread(GetCurrentThread()); DetourAttach(&(PVOID&)pGetModuleFileNameA, MyGetModuleFileNameA); DetourAttach(&(PVOID&)pGetModuleFileNameW, MyGetModuleFileNameW); DetourAttach(&(PVOID&)pGetModuleHandleA, MyGetModuleHandleA); DetourAttach(&(PVOID&)pGetModuleHandleW, MyGetModuleHandleW); LONG err = DetourTransactionCommit(); if (err != NO_ERROR) return 0; // IMAGE_DOS_HEADER *pDosHeader = (IMAGE_DOS_HEADER *) hMainAsm; IMAGE_NT_HEADERS *pNtHeaders = (IMAGE_NT_HEADERS *) (pDosHeader->e_lfanew + (ULONG_PTR) pDosHeader); if (pNtHeaders->OptionalHeader.ImageBase != (ULONG_PTR) pDosHeader) FixReloc(pDosHeader, pNtHeaders); FixIAT(pDosHeader, pNtHeaders); // retrieve entry point VOID *pEntryPoint = (VOID *) (pNtHeaders->OptionalHeader.AddressOfEntryPoint + (ULONG_PTR) pDosHeader); __asm { jmp pEntryPoint } return 0; } HMODULE WINAPI MyGetModuleHandleW(LPCWSTR lpModuleName) { if (lpModuleName == NULL) return pMainBaseAddr; return pGetModuleHandleW(lpModuleName); } HMODULE WINAPI MyGetModuleHandleA(LPCSTR lpModuleName) { if (lpModuleName == NULL) return pMainBaseAddr; return pGetModuleHandleA(lpModuleName); } DWORD WINAPI MyGetModuleFileNameA(HMODULE hModule, LPCH lpFilename, DWORD nSize) { if (hModule == NULL) { strcpy_s(lpFilename, nSize, MainAsmNameA); return (DWORD) strlen(lpFilename); } return pGetModuleFileNameA(hModule, lpFilename, nSize); } DWORD WINAPI MyGetModuleFileNameW(HMODULE hModule, LPWCH lpFilename, DWORD nSize) { if (hModule == NULL) { wcscpy_s(lpFilename, nSize, MainAsmNameW); return (DWORD) wcslen(lpFilename); } return pGetModuleFileNameW(hModule, lpFilename, nSize); } // x64 compatible VOID FixIAT(VOID *pBase, IMAGE_NT_HEADERS *pNtHeaders) { if (pNtHeaders->OptionalHeader.DataDirectory [IMAGE_DIRECTORY_ENTRY_IMPORT].VirtualAddress == 0) return; IMAGE_IMPORT_DESCRIPTOR *pImpDescr = (IMAGE_IMPORT_DESCRIPTOR *) (pNtHeaders->OptionalHeader.DataDirectory [IMAGE_DIRECTORY_ENTRY_IMPORT].VirtualAddress + (ULONG_PTR) pBase); DWORD dwOldIATProtect; VOID *pIAT = NULL; if (pNtHeaders->OptionalHeader.DataDirectory [IMAGE_DIRECTORY_ENTRY_IAT].VirtualAddress != 0) { VOID *pIAT = (VOID *) (pNtHeaders->OptionalHeader.DataDirectory [IMAGE_DIRECTORY_ENTRY_IAT].VirtualAddress + (ULONG_PTR) pBase); VirtualProtect(pIAT, pNtHeaders->OptionalHeader.DataDirectory [IMAGE_DIRECTORY_ENTRY_IAT].Size, PAGE_EXECUTE_READWRITE, &dwOldIATProtect); } while (pImpDescr->Name != 0) { char *DllName = (char *) (pImpDescr->Name + (ULONG_PTR) pBase); HMODULE hImpDll = LoadLibraryA(DllName); if (hImpDll == NULL) continue; THUNK *pThunk; if (pImpDescr->OriginalFirstThunk) pThunk = (THUNK *)(pImpDescr->OriginalFirstThunk + (ULONG_PTR) pBase); else pThunk = (THUNK *)(pImpDescr->FirstThunk + (ULONG_PTR) pBase); THUNK *pIATThunk = (THUNK *) (pImpDescr->FirstThunk + (ULONG_PTR) pBase); while (*pThunk) { if (IS_FLAG(*pThunk, IMAGE_ORDINAL_FLAG)) { *pIATThunk = (THUNK) GetProcAddress(hImpDll, (LPCSTR) (*pThunk ^ IMAGE_ORDINAL_FLAG)); } else { char *pImpFunc = (char *) (sizeof (WORD) + ((ULONG_PTR) *pThunk) + ((ULONG_PTR) pBase)); *pIATThunk = (THUNK) GetProcAddress(hImpDll, pImpFunc); } pThunk++; pIATThunk++; } pImpDescr++; } if (pIAT) { VirtualProtect(pIAT, pNtHeaders->OptionalHeader.DataDirectory [IMAGE_DIRECTORY_ENTRY_IAT].Size, dwOldIATProtect, &dwOldIATProtect); } } // x86 recycled code from an older article VOID FixReloc(VOID *pBase, IMAGE_NT_HEADERS *pNtHeaders) { // // Set first section to writeable in order to fix // the relocations in the code // IMAGE_SECTION_HEADER *pCodeSect = (IMAGE_SECTION_HEADER *) IMAGE_FIRST_SECTION(pNtHeaders); VOID *pCode = (VOID *) (pCodeSect->VirtualAddress + (ULONG_PTR) pBase); DWORD dwOldCodeProtect; VirtualProtect(pCode, pCodeSect->Misc.VirtualSize, PAGE_READWRITE, &dwOldCodeProtect); // // Relocate // DWORD Delta = (DWORD)(((ULONG_PTR) pBase) - pNtHeaders->OptionalHeader.ImageBase); DWORD RelocRva; if (!(RelocRva = pNtHeaders->OptionalHeader.DataDirectory [IMAGE_DIRECTORY_ENTRY_BASERELOC].VirtualAddress)) return; IMAGE_BASE_RELOCATION *ImgBaseReloc = (IMAGE_BASE_RELOCATION *) (RelocRva + (ULONG_PTR) pBase); WORD *wData; do { if (!ImgBaseReloc->SizeOfBlock) break; UINT nItems = (ImgBaseReloc->SizeOfBlock - IMAGE_SIZEOF_BASE_RELOCATION) / sizeof (WORD); wData = (WORD *)(IMAGE_SIZEOF_BASE_RELOCATION + (ULONG_PTR) ImgBaseReloc); for (UINT i = 0; i < nItems; i++) { DWORD Offset = (*wData & 0xFFF) + ImgBaseReloc->VirtualAddress; DWORD Type = *wData >> 12; if (Type != IMAGE_REL_BASED_ABSOLUTE) { DWORD *pBlock = (DWORD *)(Offset + (ULONG_PTR) pBase); *pBlock += Delta; } wData++; } ImgBaseReloc = (PIMAGE_BASE_RELOCATION) wData; } while (*(DWORD *) wData); // // Restore memory settings // VirtualProtect(pCode, pCodeSect->Misc.VirtualSize, dwOldCodeProtect, &dwOldCodeProtect); } |
The complete source code and the binary files can be downloaded from here:
This code just loads a .NET assembly. In order to achieve the deployment of a .NET framework, it is necessary to hook registry APIs and file system ones such as LoadLibrary as well. In the next paragraph I'm going to address registry virtualization which brings us one step forward.
I wouldn't have written this paragraph if I hadn't already had the material which I'm going to present. One of my unfinished (due to the lack of time) articles is related to virtualization. Many months ago I wrote a registry virtualizer.
The main form (VirtualReg Manager) of this tool provides the visual interface to create a virtual registry. This can also be achieved through command line, as we'll see later. One can decide whether to virtualize a key along with its subkeys or not.
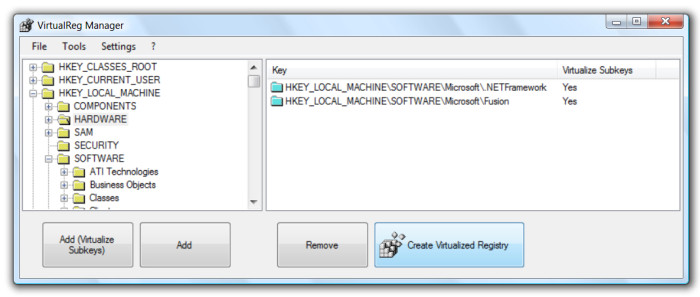
The virtual registry is an XML database. The format of this XML file looks like this:
<?xml version="1.0"
encoding="utf-8"?>
<VIRTUALREG>
<KEY Name="HKEY_LOCAL_MACHINE">
<SUBKEYS>
<KEY Name="SOFTWARE">
<SUBKEYS>
<KEY Name="Microsoft">
<SUBKEYS>
<KEY Name="Fusion">
<VALUES>
<VALUE Name="ZapQuotaInKB" Type="REG_DWORD">F4240</VALUE>
<VALUE Name="DisableCacheViewer"
Type="REG_BINARY">AQAQAA==</VALUE>
<VALUE Name="ForceLog" Type="REG_DWORD">1</VALUE>
<VALUE Name="LogPath" Type="REG_SZ">YwA6AFwAAAA=</VALUE>
</VALUES>
<SUBKEYS>
<KEY Name="GACChangeNotification">
<SUBKEYS>
<KEY Name="Default">
<VALUES>
<VALUE
Name="Accessibility,1.0.5000.0,,b03f5f7f11d50a3a"
Type="REG_BINARY">yEWDMkwyxgE=</VALUE>
<VALUE Name="cscompmgd,7.0.5000.0,,b03f5f7f11d50a3a"
Type="REG_BINARY">ROfXLkwyxgE=</VALUE>
<VALUE
Name="CustomMarshalers,1.0.5000.0,,b03f5f7f11d50a3a"
Type="REG_BINARY">yEWDMkwyxgE=</VALUE>
Numbers are stored in hex format, whereas all other data is base64 encoded. The virtual registry file can be edited with VirtualReg Editor (vregedit), which is very user-friendly as its interface is identical to regedit's one.
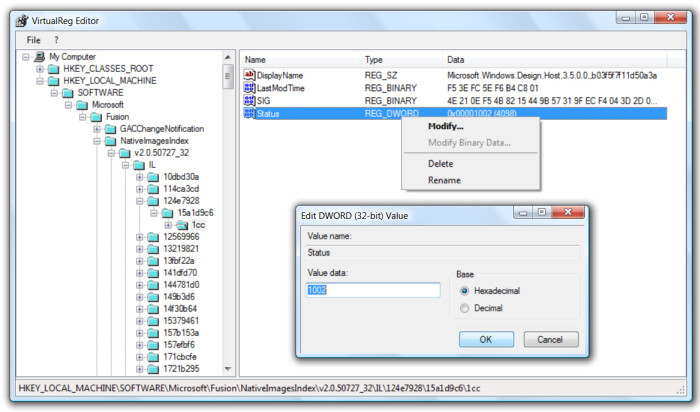
Creating a virtual registry from the GUI is okay for manual task, but tools can use the program's command line to generate a virtual registry. In order to do that, a ".tovreg" file has to be passed as command line to the program. A tovreg file has this syntax:
[OPTIONS]
output="c:\....\fusion.vreg"
[HKEY_CLASSES_ROOT\CLSID]
[HKEY_LOCAL_MACHINE\Software\Microsoft\Fusion]
subkeys=true
As one can see, it's a simply ini file. If the "subkeys" parameter is missing, then subkeys are not virtualized.
As this is part of an unfinished article, I have not written the monitor to retrieve the keys to virtualize yet. However, it's quite easy to write one or, being very lazy, using the log generated by Russinovich's Process Monitor is also an option. The catched keys should be virtualized without their subkeys, as this might in some cases result in a much to big virtual registry with unnecessary keys.
Feel free to include this tool in your freeware.
Since the code generation for native images is platform specific, it might as well imply optimizations which cannot work on other CPUs. An example of this could the use of a specific version of SSE instructions which are not available on every architecture. This problem could be "solved" by making ngen believe that it is running on an older (or different) CPU, but this is just a mess.
I'm not in favor of personal opinions inside technical articles, but it is necessary to say something about this, since one might ask me why I'm not writing a Native Framework Deployment service myself. With the information provided in this article it would take no longer than a month to provide a commercial product. The reason why I don't do it is simply because I believe it is unprofessional and technically speaking a mess. It might as well always work, but no one in his right mind would deploy every .NET assembly with a subset of the .NET framework. Deploying 40 MBs or more of data for a simple assembly is not a real solution. In fact, it's not a solution at all.
I was tempted to write a complete demonstration of such a protection (without the merging part, of course) for this article and it would have taken me no longer than a few days, but it has some drawbacks. Since I'm not interested in developing a commercial solution around this concept, someone else might simply re-use the code. Even now there's not much to do, but at least one's got to work on it a bit before having something to make money out of. However, I am all in favour of reversers writing a demonstration just for fun and giving it away for free. Yes, it ought to be free. It is not technically complicate and shouldn't be commercialized at all.
In this paragraph I'm going to show how it is possible to do the work which is being done when native images are being loaded by taking the JIT's place. The code contained in native images needs to be fixed: many references have to be solved at runtime like, for instance, external calls. I'm not showing a method to actually native compile .NET assemblies, since taking the place of the JIT is not only complicated, but also unlikely to work in future versions of the .NET framework. In fact, what I'm writing works on the .NET framework 2 and 3, but it seems that the new framework 3.5 SP1 changed lots of things and I already noticed that what I'm doing doesn't work on that version installed on Vista x64. This is rather unimportant and I'm not interested in digging to solve the problem, since what I'm doing here is only a hack to give a better understanding of how the JIT works, which will turn out useful in the next paragraphs. It will also prove the point of my final conclusions about .NET native compiling.
The test asssembly used in this paragraph is rebtest.exe: an assembly I already used to test Rebel.NET. The application is very simple, it's just a form with a text box and a button. When the user clicks the button, it checks whether the password inserted in the text box is right or not. If not, it shows the message box: "Wrong password!". Here's the MSIL code of the button click event:
| .method private hidebysig instance void button1_Click(object sender, class [mscorlib]System.EventArgs e) cil managed { // Code size 43 (0x2b) .maxstack 8 IL_0000: ldarg.0 IL_0001: ldarg.0 IL_0002: ldfld class [System.Windows.Forms]System.Windows.Forms.TextBox rebtest.Form1::textBox1 IL_0007: callvirt instance string [System.Windows.Forms]System.Windows.Forms.Control::get_Text() IL_000c: call instance bool rebtest.Form1::CheckPassword(string) IL_0011: brfalse.s IL_001f IL_0013: ldstr "Right password!" IL_0018: call valuetype System.Windows.Forms.DialogResult System.Windows.Forms.MessageBox::Show(string) IL_001d: pop IL_001e: ret IL_001f: ldstr "Wrong password!" IL_0024: call valuetype System.Windows.Forms.DialogResult System.Windows.Forms.MessageBox::Show(string) IL_0029: pop IL_002a: ret } // end of method Form1::button1_Click |
Let's look at the differences of the native code produced from this MSIL code on two different computers:
| Code A | Code B |
| 00000000 push esi 00000001 mov esi, ecx 00000003 mov ecx, [esi+0x140] 00000009 mov eax, [ecx] 0000000B call [eax+0x164] 00000011 mov edx, [0x238b9bc] 00000017 mov ecx, eax 00000019 call 0x7426edd0 0000001E and eax, 0xff 00000023 jz 0x2c 00000025 mov eax, 0x1 0000002A jmp 0x2e 0000002C xor eax, eax 0000002E test eax, eax 00000030 jz 0x42 00000032 mov ecx, [0x238b9c0] 00000038 call [0x5102544] 0000003E pop esi 0000003F ret 0x4 00000042 mov ecx, [0x238b9c4] 00000048 call [0x5102544] 0000004E pop esi 0000004F ret 0x4 |
00000000 push esi 00000001 mov esi, ecx 00000003 mov ecx, [esi+0x140] 00000009 mov eax, [ecx] 0000000B call [eax+0x164] 00000011 mov edx, [0x385b9bc] 00000017 mov ecx, eax 00000019 call 0x742ff5b0 0000001E and eax, 0xff 00000023 jz 0x2c 00000025 mov eax, 0x1 0000002A jmp 0x2e 0000002C xor eax, eax 0000002E test eax, eax 00000030 jz 0x42 00000032 mov ecx, [0x385b9c0] 00000038 call [0x5053524] 0000003E pop esi 0000003F ret 0x4 00000042 mov ecx, [0x385b9c4] 00000048 call [0x5053524] 0000004E pop esi 0000004F ret 0x4 |
Even in this small method many things are solved at runtime. In this particular case we have a ldfld, a callvirt, a ldstr and a call. One thing that should be noted is that this assembly code is using fastcalls storing the first argument in ecx and the second one in edx.
In order to understand how to solve these references, it is necessary to understand how the JIT works internally. In the first article, I introduced the compileMethod function, but I only focused on its first two arguments: ICorJitInfo and CORINFO_METHOD_INFO. What I have not discussed yet are its last two: nativeEntry and nativeSizeOfCode. Two pointers used to retrieve the native code's address and size. One could, of course, hook the compileMethod to retrieve the native code of a method after having called the original compileMethod function (which isn't very useful) or one could actually use these two arguments to inject his own native code. And that's exactly what I'm going to do. But I'm not injecting any kind of code. No, I'm going to inject native .NET code by solving internal references.
Let's start from the compileMethod function:
| /*****************************************************************************
* The main JIT function */ //Note: this assumes that the code produced by fjit is fully relocatable, i.e. requires //no fixups after it is generated when it is moved. In particular it places restrictions //on the code sequences used for static and non virtual calls and for helper calls among //other things,i.e. that pc relative instructions are not used for references to things outside of the //jitted method, and that pc relative instructions are used for all references to things //within the jitted method. To accomplish this, the fjitted code is always reached via a level //of indirection. CorJitResult __stdcall FJitCompiler::compileMethod ( ICorJitInfo* compHnd, /* IN */ CORINFO_METHOD_INFO* info, /* IN */ unsigned flags, /* IN */ BYTE ** entryAddress, /* OUT */ ULONG * nativeSizeOfCode /* OUT */ ) { #if defined(_DEBUG) || defined(LOGGING) // make a copy of the ICorJitInfo vtable so that I can log mesages later // this was made non-static due to a VC7 bug static void* ijitInfoVtable; ijitInfoVtable = *((void**) compHnd); logCallback = (ICorJitInfo*) &ijitInfoVtable; #endif if(!FJitCompiler::GetJitHelpers(compHnd)) return CORJIT_INTERNALERROR; // NOTE: should the properties of the FJIT change such that it // would have to pay attention to specific IL sequence points or // local variable liveness ranges for debugging purposes, we would // query the Runtime and Debugger for such information here, FJit* fjitData=NULL; CorJitResult ret = CORJIT_INTERNALERROR; unsigned char* savedCodeBuffer = NULL; unsigned savedCodeBufferCommittedSize = 0; unsigned int codeSize = 0; unsigned actualCodeSize; #if defined(_DEBUG) || defined(LOGGING) const char *szDebugMethodName = NULL; const char *szDebugClassName = NULL; szDebugMethodName = compHnd->getMethodName(info->ftn, &szDebugClassName ); #endif #ifdef _DEBUG static ConfigMethodSet fJitBreak; fJitBreak.ensureInit(L"JitBreak"); if (fJitBreak.contains(szDebugMethodName, szDebugClassName, PCCOR_SIGNATURE(info->args.sig))) _ASSERTE(!"JITBreak"); // Check if need to print the trace static ConfigDWORD fJitTrace; if ( fJitTrace.val(L"JitTrace") ) printf( "Method %s Class %s \n",szDebugMethodName, szDebugClassName ); #endif PAL_TRY // for PAL_FINALLY PAL_TRY // for PAL_EXCEPT { fjitData = FJit::GetContext(compHnd, info, flags); _ASSERTE(fjitData); // if GetContext fails for any reason it throws an exception _ASSERTE(fjitData->opStack_len == 0); // stack must be balanced at beginning of method codeSize = ROUND_TO_PAGE(info->ILCodeSize * CODE_EXPANSION_RATIO); #ifdef LOGGING static ConfigMethodSet fJitCodeLog; fJitCodeLog.ensureInit(L"JitCodeLog"); fjitData->codeLog = fJitCodeLog.contains(szDebugMethodName, szDebugClassName, PCCOR_SIGNATURE(info->args.sig)); if (fjitData->codeLog) codeSize = ROUND_TO_PAGE(info->ILCodeSize * 64); #endif BOOL jitRetry = FALSE; // this is set to false unless we get an exception because // of underestimation of code buffer size do { // the following loop is expected to execute only once, // except when we underestimate the size of the code buffer, // in which case, we try again with a larger codeSize if (codeSize < MIN_CODE_BUFFER_RESERVED_SIZE) { if (codeSize > fjitData->codeBufferCommittedSize) { if (fjitData->codeBufferCommittedSize > 0) { unsigned AdditionalMemorySize = codeSize - fjitData->codeBufferCommittedSize; if (AdditionalMemorySize > PAGE_SIZE) { unsigned char* additionalMemory = (unsigned char*) VirtualAlloc(fjitData->codeBuffer+fjitData->codeBufferCommittedSize+PAGE_SIZE, AdditionalMemorySize-PAGE_SIZE, MEM_COMMIT, PAGE_READWRITE); if (additionalMemory == NULL) { ret = CORJIT_OUTOFMEM; goto Done; } _ASSERTE(additionalMemory == fjitData->codeBuffer+ fjitData->codeBufferCommittedSize+PAGE_SIZE); } // recommit the guard page VirtualAlloc(fjitData->codeBuffer + fjitData->codeBufferCommittedSize, PAGE_SIZE, MEM_COMMIT, PAGE_READWRITE); fjitData->codeBufferCommittedSize = codeSize; } else { /* first time codeBuffer being initialized */ savedCodeBuffer = fjitData->codeBuffer; fjitData->codeBuffer = (unsigned char*)VirtualAlloc(fjitData->codeBuffer, codeSize, MEM_COMMIT, PAGE_READWRITE); if (fjitData->codeBuffer == NULL) { fjitData->codeBuffer = savedCodeBuffer; ret = CORJIT_OUTOFMEM; goto Done; } fjitData->codeBufferCommittedSize = codeSize; } _ASSERTE(codeSize == fjitData->codeBufferCommittedSize); unsigned char* guardPage = (unsigned char*)VirtualAlloc(fjitData->codeBuffer + codeSize, PAGE_SIZE, MEM_COMMIT, PAGE_READONLY); if (guardPage == NULL) { ret = CORJIT_OUTOFMEM; goto Done; } } } else { // handle larger than MIN_CODE_BUFFER_RESERVED_SIZE methods savedCodeBuffer = fjitData->codeBuffer; savedCodeBufferCommittedSize = fjitData->codeBufferCommittedSize; fjitData->codeBuffer = (unsigned char*)VirtualAlloc(NULL, codeSize, MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE); if (fjitData->codeBuffer == NULL) { // Make sure that the saved buffer is freed in the destructor fjitData->codeBuffer = savedCodeBuffer; ret = CORJIT_OUTOFMEM; goto Done; } fjitData->codeBufferCommittedSize = codeSize; } unsigned char* entryPoint; actualCodeSize = codeSize; PAL_TRY { FJitResult FJitRet; jitRetry = false; FJitRet = fjitData->jitCompile(&entryPoint,&actualCodeSize); if (FJitRet == FJIT_VERIFICATIONFAILED) { if (!(flags & CORJIT_FLG_IMPORT_ONLY)) // If we get a verification failed error, just map it to OK as // it's already been dealt with. ret = CORJIT_OK; else // if we are in "Import only" mode, we are actually verifying // generic code. It's important that we don't return CORJIT_OK, // because we want to skip the code generation phase. ret = CORJIT_BADCODE; } else if (FJitRet == FJIT_JITAGAIN) { jitRetry = true; ret = CORJIT_INTERNALERROR; } else // Otherwise cast it to a CorJitResult ret = (CorJitResult)FJitRet; if ( ret == CORJIT_OK ) ret = fjitData->fixupTable->resolve(fjitData->mapping, fjitData->codeBuffer, jitRetry ); if ( jitRetry ) { fjitData->ReleaseContext(); fjitData = FJit::GetContext(compHnd, info, flags); fjitData->mapInfo.savedIP = true; } } |
The function is actually much bigger, but I only pasted the interesting part for us. Among the last lines of code I pasted you can see that compileMethod is calling the function jitCompile. This is the main function of the JIT. It's a very huge function since it contains the switch to handle every MSIL opcode. I'm going to past a "small" part of the function here to give you an idea of the magnitude.
| /************************************************************************************/ /* jit the method. if successful, return number of bytes jitted, else return 0 */ FJitResult FJit::jitCompile( BYTE ** ReturnAddress, unsigned * ReturncodeSize ) { /***************************************************************************** * The following macro reads a value from the IL stream. It checks that the size * of the object doesn't exceed the length of the stream. It also checks that * the data has not been previously read and marks it as read, unless the "reread" * variable is set to true. *****************************************************************************/ #define GET(val, type, reread) \ { \ unsigned int size_operand; \ VALIDITY_CHECK( inPtr + sizeof(type) <= inBuffEnd ); \ for ( size_operand = 0; size_operand < sizeof(type) && !reread; size_operand++ ) \ VALIDITY_CHECK(!state[inPtr- inBuff+size_operand].isJitted) \ switch(sizeof(type)) { \ case 1: val = (type)*inPtr; break; \ case 2: val = (type)GET_UNALIGNED_VAL16(inPtr); break; \ case 4: val = (type)GET_UNALIGNED_VAL32(inPtr); break; \ case 8: val = (type)GET_UNALIGNED_VAL64(inPtr); break; \ default: val = (type)0; _ASSERTE(!"Invalid size"); break; \ } \ inPtr += sizeof(type); \ for ( size_operand = 1; size_operand <= sizeof(type) && !reread; size_operand++ ) \ state[inPtr-inBuff-size_operand].isJitted = true; \ } #define LEAVE_CRIT \ if (methodInfo->args.hasThis()) { \ emit_WIN32(emit_LDVAR_I4(offsetOfRegister(0))) \ emit_WIN64(emit_LDVAR_I8(offsetOfRegister(0))); \ emit_EXIT_CRIT(); \ } \ else { \ void* syncHandle; \ syncHandle = jitInfo->getMethodSync(methodInfo->ftn); \ emit_EXIT_CRIT_STATIC(syncHandle); \ } #define ENTER_CRIT \ if (methodInfo->args.hasThis()) { \ emit_WIN32(emit_LDVAR_I4(offsetOfRegister(0))) \ emit_WIN64(emit_LDVAR_I8(offsetOfRegister(0))); \ emit_ENTER_CRIT(); \ } \ else { \ void* syncHandle; \ syncHandle = jitInfo->getMethodSync(methodInfo->ftn); \ emit_ENTER_CRIT_STATIC(syncHandle); \ } #define CURRENT_INDEX (inPtr - inBuff) TailCallForbidden = !!((methodInfo->args.callConv & CORINFO_CALLCONV_MASK) == CORINFO_CALLCONV_VARARG); // if set, no tailcalls allowed. Initialized to FALSE. When a security test // changes it to TRUE, it remains TRUE for the duration of the jitting of the function outBuff = codeBuffer; CORINFO_METHOD_HANDLE methodHandle= methodInfo->ftn; unsigned int len = methodInfo->ILCodeSize; // IL size inBuff = methodInfo->ILCode; // IL bytes inBuffEnd = &inBuff[len]; // end of IL entryAddress = ReturnAddress; codeSize = ReturncodeSize; // Information about arguments and locals offsetVarArgToken = sizeof(prolog_frame); // Local variables declared for convenience and flags unsigned offset; unsigned address; signed int i4; int merge_state; FJitResult JitResult = FJIT_OK; unsigned char opcode_val; InstStart = 0; DelegateStart = 0; DelegateMethodRef = 0; UnalignedOffset = (unsigned)-1; JitAgain: MadeTailCall = false; // if a tailcall has been made and subsequently TailCallForbidden is set to TRUE, // we will rejit the code, disallowing tailcalls. inRegTOS = false; // flag indicating if the top of the stack is in a register controlContinue = true; // does control we fall thru to next il instr inPtr = inBuff; // Set the current IL offset to the start of the IL buffer outPtr = outBuff; // Set the current output buffer position to the start of the buffer codeGenState = FJIT_OK; // Reset the global error flag JitResult = FJIT_OK; // Reset the result flag for simple operations that don't set it UnalignedAccess = false; // Reset the unaligned access flag #ifdef _DEBUG didLocalAlloc = false; #endif // Can not jit a native method VALIDITY_CHECK(!(methodAttributes & (CORINFO_FLG_NATIVE))); // Zero sized methods are not allowed VALIDITY_CHECK(methodInfo->ILCodeSize > 0); // Can not jit methods with shared bodies VALIDITY_CHECK(!(methodAttributes & CORINFO_FLG_SHAREDINST) ); *(entryAddress) = outPtr; #if defined(_DEBUG) static ConfigMethodSet fJitHalt; fJitHalt.ensureInit(L"JitHalt"); if (fJitHalt.contains(szDebugMethodName, szDebugClassName, PCCOR_SIGNATURE(methodInfo->args.sig))) { emit_break(); } #endif //Skip verification if possible JitVerify = !(flags & CORJIT_FLG_SKIP_VERIFICATION); IsVerifiableCode = true; // assume the code is verifiable unless proven otherwise // load any constraints for verification, detecting and rejecting cycles if (JitVerify) { BOOL hasCircularClassConstraints = FALSE; BOOL hasCircularMethodConstraints = FALSE; jitInfo->initConstraintsForVerification(methodHandle,&hasCircularClassConstraints, &hasCircularMethodConstraints); VERIFICATION_CHECK(!hasCircularClassConstraints); VERIFICATION_CHECK(!hasCircularMethodConstraints); } #if defined(_SPARC_) || defined(_PPC_) // Check if the offset of the vararg token has been computed correctly offsetVarArgToken += ( methodInfo->args.hasThis() ? sizeof( void * ) : 0 ) + ( methodInfo->args.hasRetBuffArg() && EnregReturnBuffer ? sizeof( void * ) : 0 ); #endif // it may be worth optimizing the following to only initialize locals so as to cover all refs. unsigned int localWords = (localsFrameSize+sizeof(void*)-1)/ sizeof(void*); emit_prolog(localWords); if (flags & CORJIT_FLG_PROF_ENTERLEAVE) { BOOL bHookFunction; void *eeHandle; void *profilerHandle; BOOL bIndirected; jitInfo->GetProfilingHandle(methodHandle, &bHookFunction, &eeHandle, &profilerHandle, &bIndirected); if (bHookFunction) { _ASSERTE(!bIndirected); // FJIT does not handle NGEN case _ASSERTE(!inRegTOS); ULONG func = (ULONG) jitInfo->getHelperFtn(CORINFO_HELP_PROF_FCN_ENTER); _ASSERTE(func != NULL); emit_callhelper_prof4(func, (CorJitFlag) CORINFO_HELP_PROF_FCN_ENTER, eeHandle, profilerHandle, NULL, // FRAME_INFO (see definition of FunctionEnter2 in corprof.idl) NULL); // ARG_INFO (see definition of FunctionEnter2 in corprof.idl) } } // Do we need to insert a "JustMyCode" callback? if (flags & CORJIT_FLG_DEBUG_CODE) { CORINFO_JUST_MY_CODE_HANDLE *pDbgHandle; CORINFO_JUST_MY_CODE_HANDLE dbgHandle = jitInfo->getJustMyCodeHandle(methodHandle, &pDbgHandle); _ASSERTE(!dbgHandle || !pDbgHandle); if (dbgHandle || pDbgHandle) emit_justmycode_callback( dbgHandle, pDbgHandle ); } #ifdef LOGGING if (codeLog) { emit_log_entry(szDebugClassName, szDebugMethodName); } #endif // Get sequence points unsigned nextSequencePoint = 0; if (flags & CORJIT_FLG_DEBUG_INFO) { getSequencePoints(jitInfo,methodHandle,&cSequencePoints,&sequencePointOffsets,&offsetsImplicit); } else { cSequencePoints = 0; offsetsImplicit = ICorDebugInfo::NO_BOUNDARIES; } mapInfo.prologSize = outPtr-outBuff; // note: entering of the critical section is not part of the prolog mapping->add(CURRENT_INDEX,(unsigned)(outPtr - outBuff)); if (methodAttributes & CORINFO_FLG_SYNCH) { ENTER_CRIT; } // Verify the exception handlers' table int ver_exceptions = verifyHandlers(); VALIDITY_CHECK( ver_exceptions != FAILED_VALIDATION ); VERIFICATION_CHECK( ver_exceptions != FAILED_VERIFICATION ); // Initialize the state map with the exception handling information initializeExceptionHandling(); bool First = true; popSplitStack = false; // Start jitting at the next offset on the split stack UncondBranch = false; // Executing an unconditional branch LeavingTryBlock = false; // Executing a "leave" from a try block LeavingCatchBlock = false; // Executing a "leave" from a catch block FinishedJitting = false; // Finished jitting the IL stream makeClauseEmpty(¤tClause); _ASSERTE(!inRegTOS); while (!FinishedJitting) { //INDEBUG( printf("IL offset: %x PopStack: %d StackEmpty: %d\n", CURRENT_INDEX, // popSplitStack, SplitOffsets.isEmpty() );) START_LOOP: // If we jitted the last statement or an uncondtional branch with jitted target // we need to restart at the next split offset if ( inPtr >= inBuffEnd || popSplitStack ) { // Remove the IL offsets that's already been jitted while ( !SplitOffsets.isEmpty() && state[SplitOffsets.top()].isJitted ) (void)SplitOffsets.popOffset(); //INDEBUG(SplitOffsets.dumpStack();) // We reached the end of the IL opcode stream, but not all code has been jitted // Pop the offset from the split offsets stack if (!SplitOffsets.isEmpty()) { inPtr = (unsigned char *)&inBuff[SplitOffsets.popOffset()]; //INDEBUG(printf("Starting jitting at %d \n", inPtr-inBuff );) // Treat a split as a forward jump controlContinue = false; // Reset flag popSplitStack = false; } else { // Check for a fall through at the end of the function VALIDITY_CHECK( popSplitStack || inBuff[InstStart] == CEE_THROW ); goto END_JIT_LOOP; } } // Check if max stack value has been exceded VERIFICATION_CHECK( methodInfo->maxStack >= opStack_len ); //INDEBUG(if (JitVerify) printf("IL offset is %x\n", CURRENT_INDEX );) // Guard against a fall through into/from a catch/finally/filter VALIDITY_CHECK(!(state[CURRENT_INDEX].isHandler) && !(state[CURRENT_INDEX].isFilter) && !(state[CURRENT_INDEX].isEndBlock) || !controlContinue || UncondBranch ); UncondBranch = false; // This flag is only used to check for fall through if (controlContinue) { if (state[CURRENT_INDEX].isJmpTarget && inRegTOS != state[CURRENT_INDEX].isTOSInReg) { if (inRegTOS) { deregisterTOS; } else { enregisterTOS; } } } else { // controlContinue == false unsigned int label = ver_stacks.findLabel(CURRENT_INDEX); if (label == LABEL_NOT_FOUND) { CHECK_POP_STACK(opStack_len); inRegTOS = false; } else { opStack_len = ver_stacks.setStackFromLabel(label, opStack, opStack_size); inRegTOS = state[CURRENT_INDEX].isTOSInReg; } controlContinue = true; } //Check if this IL offset has already been jitted. Note, that to see if //an offset has been jitted we need to check that it is not in skipped code //intervals and that an offset equal to or above it has been jitted if ( state[inPtr-inBuff].isJitted ) { //INDEBUG( printf("Detected jitted code: IL offset is %x\n",CURRENT_INDEX );) // The skipped code interval must just have ended // If verification is enabled we need to compare the current state of the stack with the saved one merge_state = verifyStacks(CURRENT_INDEX, 0); VERIFICATION_CHECK( merge_state ); if ( JitVerify && merge_state == MERGE_STATE_REJIT ) { resetState(false); goto JitAgain; } // Emit a jump to the jitted code ilrel = CURRENT_INDEX; if (state[inPtr-inBuff].isTOSInReg) { enregisterTOS; } else { deregisterTOS; } address = mapping->pcFromIL(inPtr-inBuff); VALIDITY_CHECK(address > 0 ); emit_jmp_abs_address(CEE_CondAlways, address + (unsigned)outBuff, true); // INDEBUG(printf("Emitted a jump to %d\n", outPtr+address-outBuff);) // Remove the IL offsets that's already been jitted while ( !SplitOffsets.isEmpty() && state[SplitOffsets.top()].isJitted ) (void)SplitOffsets.popOffset(); // Pop the offset from the split offsets stack if (!SplitOffsets.isEmpty()) { inPtr = (unsigned char *)&inBuff[SplitOffsets.popOffset()]; //INDEBUG(printf("Starting jitting at %d \n", inPtr-inBuff );) // Treat a split as a forward jump controlContinue = false; //INDEBUG(SplitOffsets.dumpStack();) goto START_LOOP; } else goto END_JIT_LOOP; } // If the current offset is a beginning of a try block, it is necessary to push the addresses of // associated handlers onto the split offsets stack in the correct order if (state[CURRENT_INDEX].isTry) { //INDEBUG(printf("Pushed Handlers at %x\n", CURRENT_INDEX );) // The stack has to be empty on an entry to a try block VALIDITY_CHECK(isOpStackEmpty()); // Push the starting offset of the try block onto the split offsets stack SplitOffsets.pushOffset(CURRENT_INDEX); // Push the starting addresses of all the handlers onto the split offsets stack pushHandlerOffsets(CURRENT_INDEX); // Emit a jump to the start of the try block fixupTable->insert((void**) outPtr); emit_jmp_abs_address(CEE_CondAlways, CURRENT_INDEX, false); //INDEBUG(SplitOffsets.dumpStack();) state[CURRENT_INDEX].isTry = 0; // Reset the flag once the handlers have been pushed onto the stack // Start jitting the first handler popSplitStack = true; controlContinue = false; First = false; continue; } // This IL opcode will be jitted if (!First) mapping->add(CURRENT_INDEX,(unsigned)(outPtr - outBuff)); First = false; if (state[CURRENT_INDEX].isHandler) { if ( (offsetsImplicit & ICorDebugInfo::CALL_SITE_BOUNDARIES) != 0 ) emit_sequence_point_marker(); unsigned int nestingLevel = Compute_EH_NestingLevel(inPtr-inBuff); emit_storeTOS_in_JitGenerated_local(nestingLevel,state[CURRENT_INDEX].isFilter); } state[CURRENT_INDEX].isTOSInReg = inRegTOS; // Check if we are currently at a sequence point emitSequencePointPre( CURRENT_INDEX, nextSequencePoint ); // If verification is enabled we need to store the current state of the stack merge_state = verifyStacks(CURRENT_INDEX, 1); VERIFICATION_CHECK( merge_state ); if ( JitVerify && merge_state == MERGE_STATE_REJIT ) { resetState(false); goto JitAgain; } InstStart = CURRENT_INDEX; if ( InstStart == UnalignedOffset ) UnalignedAccess = true; #ifdef LOGGING ilrel = inPtr - inBuff; #endif GET(opcode_val, unsigned char, false ); OPCODE opcode = OPCODE(opcode_val); DECODE_OPCODE: #ifdef LOGGING if (codeLog && opcode != CEE_PREFIXREF && (opcode < CEE_PREFIX7 || opcode > CEE_PREFIX1)) { bool oldstate = inRegTOS; emit_log_opcode(ilrel, opcode, oldstate); inRegTOS = oldstate; } #endif switch (opcode) { case CEE_PREFIX1: GET(opcode_val, unsigned char, false); opcode = OPCODE(opcode_val + 256); goto DECODE_OPCODE; case CEE_LDARG_0: case CEE_LDARG_1: case CEE_LDARG_2: case CEE_LDARG_3: offset = (opcode - CEE_LDARG_0); // Make sure that the offset is legal (with respect to the IL encoding) VERIFICATION_CHECK(offset < 4); JitResult = compileDO_LDARG( opcode, offset); break; |
Only in the last lines of code we encounter the switch I was talking about. The switch is inside a loop (naturally) which goes on until the last opcode hasn't been jitted. As one can notice, the switch doesn't come directly after the beginning of the jitting loop. That's because before every instruction to handle the JIT performs many checks. For instance, it checks that the maximum stack size hasn't been exceeded or that the current offset isn't the benning of a try block. However, we don't care about all those things, since we don't have to perform validity checks nor implement exception handlers.
Note: the GET macro should be briefly discussed for better understanding. This macro reads a value type from the current MSIL opcode stream pointer and puts it in a variable (first argument), then it increments the stream pointer.
What I'm going to do is to inject the .NET message box displaying "Right password!". Thus, we'll have to analyze how the JIT handles the opcodes ldstr and call. This is a good way to proceed, as the ldstr opcode is very easy and gives the reader the time to adapt to the JIT logic. So, let's look at the ldstr case in the switch:
| case CEE_LDSTR: JitResult = compileCEE_LDSTR(); break; |
This is the usual syntax used to handle opcodes: a call to compileCEE_OpcodeName. Let's look at this function:
| FJitResult FJit::compileCEE_LDSTR() { unsigned int token; InfoAccessType iat; CORINFO_MODULE_HANDLE tokenScope = methodInfo->scope; GET(token, unsigned int, false); VERIFICATION_CHECK(jitInfo->isValidToken(tokenScope, token)); void* literalHnd = NULL; iat = jitInfo->constructStringLiteral(tokenScope,token, &literalHnd); // the code only ever supported the equivalent of IAT_PVALUE, this is now asserted VALIDITY_CHECK(iat == IAT_PVALUE); // Check if the string was constructed successfully VALIDITY_CHECK(literalHnd != 0); emit_WIN32(emit_LDC_I4(literalHnd)) emit_WIN64(emit_LDC_I8(literalHnd)) ; emit_LDIND_PTR(false); // Get the type handle for strings CORINFO_CLASS_HANDLE s_StringClass = jitInfo->getBuiltinClass(CLASSID_STRING); VALIDITY_CHECK( s_StringClass != NULL ); pushOp(OpType(typeRef, s_StringClass )); return FJIT_OK; } |
When looking at this function it is necessary to define what we need in order to get a string reference. We're already familiar with the GET macro and its use. We already have a string token and also a scope. We don't need to do any sort of verification. So, it all comes down to the function constructStringLiteral which is declared in dynamicmethod.cpp:
| InfoAccessType CEEDynamicCodeInfo::constructStringLiteral( CORINFO_MODULE_HANDLE moduleHnd, mdToken metaTok, void **ppInfo) { CONTRACTL { THROWS; GC_TRIGGERS; MODE_COOPERATIVE; PRECONDITION(IsDynamicScope(moduleHnd)); } CONTRACTL_END; _ASSERTE(ppInfo != NULL); *ppInfo = NULL; DynamicResolver* pResolver = GetDynamicResolver(moduleHnd); OBJECTHANDLE string = NULL; STRINGREF strRef = ObjectToSTRINGREF(pResolver->GetStringLiteral(metaTok)); GCPROTECT_BEGIN(strRef); if (strRef != NULL) { MethodDesc* pMD = pResolver->GetDynamicMethod(); string = (OBJECTHANDLE)pMD->GetModule()->GetAssembly()->Parent()->GetOrInternString(&strRef); } GCPROTECT_END(); *ppInfo = (LPVOID)string; return IAT_PVALUE; } |
I pasted the function only to show how the reference to the string is retrieved internally. It wasn't necessary for the demonstration, but I thought it's interesting since it involves GetDynamicResolver and the module handle. I have already introduced CORINFO handles in the past article, showing how they are nothing else than class pointers. In fact, GetDynamicResolver is basically just a cast:
|
inline DynamicResolver* GetDynamicResolver(CORINFO_MODULE_HANDLE module) { WRAPPER_CONTRACT; CONSISTENCY_CHECK(IsDynamicScope(module)); return (DynamicResolver*)(((size_t)module) & ~((size_t)CORINFO_MODULE_HANDLE_TYPE_MASK)); } |
To conclude the analysis of compileCEE_LDSTR, the "emit_" macros are used to generate the platform specific native code, whereas the pushOp function is part of a series of functions to handle the MSIL stack necessary for jitting to native code. I'll discuss later the MSIL stack.
This is the call opcode handler:
|
case CEE_CALL: JitResult = compileCEE_CALL(); break; |
compileCEE_CALL calls another function internally. So I'm going to paste both:
| FJitResult FJit::compileCEE_CALL() { unsigned int token; CORINFO_METHOD_HANDLE targetMethod; CORINFO_MODULE_HANDLE tokenScope = methodInfo->scope; GET(token, unsigned int, false); VERIFICATION_CHECK(jitInfo->isValidToken(tokenScope, token)); CORINFO_CALL_INFO callInfo; // Call this because the CLR "misuses" this method to activate // the target assembly (if needed). So if we would not call it // later in the game the compiled code could try to call into // the assembly which was not activated yet. // On the other hand we don't actually need any information // provided by this call. jitInfo->getCallInfo(methodInfo->ftn, tokenScope, token, 0, // constraintToken - methodInfo->ftn, CORINFO_CALLINFO_KINDONLY, & callInfo); targetMethod = jitInfo->findMethod(tokenScope, token, methodInfo->ftn); VALIDITY_CHECK(targetMethod); return this->compileHelperCEE_CALL(token, targetMethod, false /*readonly*/); } FJitResult FJit::compileHelperCEE_CALL(unsigned int token, CORINFO_METHOD_HANDLE targetMethod, bool isReadOnly /* = false */) { unsigned int argBytes, stackPadorRetBase = 0; unsigned int parentToken; CORINFO_CLASS_HANDLE targetClass, parentClass = NULL; CORINFO_SIG_INFO targetSigInfo; CORINFO_METHOD_HANDLE tokenContext= methodInfo->ftn; CORINFO_MODULE_HANDLE tokenScope = methodInfo->scope; // Get attributes for the method being called DWORD methodAttribs; methodAttribs = jitInfo->getMethodAttribs(targetMethod,methodInfo->ftn); // Get the class of the method being called targetClass = jitInfo->getMethodClass (targetMethod); // get the exact parent of the method parentToken = jitInfo->getMemberParent(tokenScope, token); parentClass = jitInfo->findClass(tokenScope, parentToken, methodInfo->ftn); // Get the attributes of the class of the method being called DWORD classAttribs; classAttribs = jitInfo->getClassAttribs(targetClass, methodInfo->ftn); // Verify that the method has an implementation i.e. it is not abstract VERIFICATION_CHECK(!(methodAttribs & CORINFO_FLG_ABSTRACT )); if (methodAttribs & CORINFO_FLG_SECURITYCHECK) { TailCallForbidden = TRUE; if (MadeTailCall) { // we have already made a tailcall, so cleanup and jit this method again if(cSequencePoints > 0) cleanupSequencePoints(jitInfo,sequencePointOffsets); resetContextState(); return FJIT_JITAGAIN; } } jitInfo->getMethodSig(targetMethod, &targetSigInfo); if (targetSigInfo.isVarArg()) jitInfo->findCallSiteSig(tokenScope,token,tokenContext,&targetSigInfo); // Verify that the arguments on the stack match the method signature int result_arg_ver = ( JitVerify ? verifyArguments( targetSigInfo, 0, false) : SUCCESS_VERIFICATION ); VALIDITY_CHECK( result_arg_ver != FAILED_VALIDATION ); VERIFICATION_CHECK( result_arg_ver != FAILED_VERIFICATION ); // Verify the this argument for non-static methods( it is not part of the method signature ) CORINFO_CLASS_HANDLE instanceClassHnd = jitInfo->getMethodClass(methodInfo->ftn); if (!( methodAttribs& CORINFO_FLG_STATIC) ) { // For arrays we don't have the correct class handle if ( classAttribs & CORINFO_FLG_ARRAY) targetClass = jitInfo->findMethodClass( tokenScope, token, tokenContext ); int result_this_ver = ( JitVerify ? verifyThisPtr(instanceClassHnd, targetClass, targetSigInfo.numArgs, false ) : SUCCESS_VERIFICATION ); VERIFICATION_CHECK( result_this_ver != FAILED_VERIFICATION ); } // Verify the constraints on the target method (including its parent) VERIFICATION_CHECK( jitInfo->satisfiesClassConstraints(parentClass)); VERIFICATION_CHECK( jitInfo->satisfiesMethodConstraints(parentClass, targetMethod)); // Verify that the method is accessible from the call site VERIFICATION_CHECK(jitInfo->canAccessMethod(methodInfo->ftn, parentClass, targetMethod, instanceClassHnd )); if (targetSigInfo.hasTypeArg()) { CORINFO_CLASS_HANDLE tokenType; // Instantiated generic method if(isReadOnly) { // when the call is readonly the Array Stub expects the type arg to // be zero emit_LDC_I(0); } else { TokenToHandle(parentToken, tokenType); } } argBytes = buildCall(&targetSigInfo, CALL_NONE, stackPadorRetBase, false ); CORINFO_CONST_LOOKUP addrInfo; jitInfo->getFunctionEntryPoint(targetMethod, IAT_VALUE, &addrInfo); VALIDITY_CHECK(addrInfo.addr); VALIDITY_CHECK(addrInfo.accessType == IAT_VALUE || addrInfo.accessType == IAT_PVALUE); emit_callnonvirt((unsigned)addrInfo.addr, (targetSigInfo.hasRetBuffArg() ? typeSizeInBytes(jitInfo, targetSigInfo.retTypeClass) : 0), addrInfo.accessType == IAT_PVALUE); return compileDO_PUSH_CALL_RESULT(argBytes, stackPadorRetBase, token, targetSigInfo, targetClass); } |
As I said earlier, ldstr was a very easy opcode to handle. The call instruction is a bit more complex, but don't get impressed, it's simple to understand. The size of the code is mainly the result of the many validity checks. compileCEE_CALL calls first getCallInfo which is, as it seems, misused to activate the assembly in which the code is contained. Then findMethod is called to retrieve the handle of the method which is being called. After that, the compileHelperCEE_CALL function is called. This function performs lots of checks: we can skip those and focus on the latter part. Among the last calls a getFunctionEntryPoint function can be spotted and that's exactly what we were looking for. The buildCall, emit_callnonvirt and compileDO_PUSH_CALL_RESULT do only build the native code calling syntax and emit the native opcodes.
The only description of getFunctionEntryPoint can be found in corinfo.h:
| // return a callable address of the function (native code). This function // may return a different value (depending on whether the method has // been JITed or not. pAccessType is an in-out parameter. The JIT // specifies what level of indirection it desires, and the EE sets it // to what it can provide (which may not be the same). virtual void __stdcall getFunctionEntryPoint( CORINFO_METHOD_HANDLE ftn, /* IN */ InfoAccessType requestedAccessType, /* IN */ CORINFO_CONST_LOOKUP * pResult, /* OUT */ CORINFO_ACCESS_FLAGS accessFlags = CORINFO_ACCESS_ANY) = 0; |
Basically, this function retrieves the callable native code of the target function. Before calling getFunctionEntryPoint it is necessary to retrieve the target method's handle. This can be achieved with findMethod.
It's now possible to write a little demonstration. As in the past article, I'm using a .NET loader to hook the JIT before loading the victim assembly. The nvcoree.dll hooks compileMethod and injects the native code which shows a .NET message box with the text "Right password!". Here's the code of nvcoree.dll:
| #include "stdafx.h" #include <CorHdr.h> #include "corinfo.h" #include "corjit.h" #include <tchar.h> extern "C" __declspec(dllexport) void HookJIT(); BOOL APIENTRY DllMain( HMODULE hModule, DWORD dwReason, LPVOID lpReserved ) { HookJIT(); return TRUE; } BOOL bHooked = FALSE; ULONG_PTR *(__stdcall *p_getJit)(); typedef int (__stdcall *compileMethod_def)(ULONG_PTR classthis, ICorJitInfo *comp, CORINFO_METHOD_INFO *info, unsigned flags, BYTE **nativeEntry, ULONG *nativeSizeOfCode); struct JIT { compileMethod_def compileMethod; }; compileMethod_def compileMethod; // // native code to inject // #define CODE_SIZE 15 BYTE Code[CODE_SIZE] = { 0x8B, 0x0D, 0x00, 0x00, 0x00, 0x00, // mov ecx, [addr] 0xFF, 0x15, 0x00, 0x00, 0x00, 0x00, // call [msgbox] 0xC2, 0x04, 0x00 // ret 4 }; int __stdcall my_compileMethod(ULONG_PTR classthis, ICorJitInfo *comp, CORINFO_METHOD_INFO *info, unsigned flags, BYTE **nativeEntry, ULONG *nativeSizeOfCode) { // // Very lazy way to identify the method to inject // const char *szMethodName = NULL; const char *szClassName = NULL; szMethodName = comp->getMethodName(info->ftn, &szClassName); if (strcmp(szMethodName, "button1_Click") == 0) { // // Retrieve string // unsigned int strToken = 0x70000063; // "Right password!" void* literalHnd = NULL; comp->constructStringLiteral(info->scope, strToken, &literalHnd); // // Retrieve method // /* * misused to activate the method's assembly * (we don't care about that) * CORINFO_CALL_INFO callInfo; comp->getCallInfo(info->ftn, info->scope, 0x0A00001E, 0, // constraintToken info->ftn, CORINFO_CALLINFO_KINDONLY, &callInfo); */ CORINFO_METHOD_HANDLE targetMethod = comp->findMethod(info->scope, 0x0A00001E, info->ftn); CORINFO_CONST_LOOKUP addrInfo; comp->getFunctionEntryPoint(targetMethod, IAT_VALUE, &addrInfo); // // Set up native code // /* * This is basically what we're doing * __asm { mov ecx, [literalHnd] call [addrInfo.addr] } */ BYTE *pCode = Code; pCode += 2; *((ULONG_PTR *) pCode) = (ULONG_PTR) literalHnd; pCode += 6; *((ULONG_PTR *) pCode) = (ULONG_PTR) addrInfo.addr; DWORD dwOldProtect; VirtualProtect(Code, CODE_SIZE, PAGE_EXECUTE_READWRITE, &dwOldProtect); *nativeEntry = Code; *nativeSizeOfCode = CODE_SIZE; return CORJIT_OK; // it's 0 as usual } int nRet = compileMethod(classthis, comp, info, flags, nativeEntry, nativeSizeOfCode); return nRet; } // // Hooks compileMethod // extern "C" __declspec(dllexport) void HookJIT() { if (bHooked) return; LoadLibrary(_T("mscoree.dll")); HMODULE hJitMod = LoadLibrary(_T("mscorjit.dll")); if (!hJitMod) return; p_getJit = (ULONG_PTR *(__stdcall *)()) GetProcAddress(hJitMod, "getJit"); if (p_getJit) { JIT *pJit = (JIT *) *((ULONG_PTR *) p_getJit()); if (pJit) { DWORD OldProtect; VirtualProtect(pJit, sizeof (ULONG_PTR), PAGE_READWRITE, &OldProtect); compileMethod = pJit->compileMethod; pJit->compileMethod = &my_compileMethod; VirtualProtect(pJit, sizeof (ULONG_PTR), OldProtect, &OldProtect); bHooked = TRUE; } } } |
Everytime the user clicks on the button, the injected code will always be called instead of the actual password check.
- Download the Native Injection Demo
The two instruction I handled were rather simple. Other opcodes like ldfld and callvirt are a bit more complicated, since they also make use of the MSIL stack, which I mentioned earlier. ldfld pops out a value from the stack which is the object whose field it is going to reference. Here's a bit of the code which jits ldfld:
| FJitResult FJit::compileCEE_LDFLD( OPCODE opcode) { unsigned address = 0; unsigned int token, parentToken; DWORD fieldAttributes; CorInfoType jitType; CORINFO_CLASS_HANDLE targetClass = NULL, parentClass = NULL; bool fieldIsStatic; CORINFO_MODULE_HANDLE tokenScope = methodInfo->scope; CORINFO_METHOD_HANDLE tokenContext = methodInfo->ftn; CORINFO_FIELD_HANDLE targetField; // Get MemberRef token for object field GET(token, unsigned int, false); VERIFICATION_CHECK(jitInfo->isValidToken(tokenScope, token)); targetField = jitInfo->findField (tokenScope, token,tokenContext); VALIDITY_CHECK(targetField); fieldAttributes = jitInfo->getFieldAttribs(targetField,methodInfo->ftn); fieldIsStatic = (fieldAttributes & CORINFO_FLG_STATIC) ? true : false; targetClass = jitInfo->findClass(tokenScope, jitInfo->getMemberParent(tokenScope, token), tokenContext); VALIDITY_CHECK(targetClass); // targetClass is the enclosing class CORINFO_CLASS_HANDLE valClass; jitType = jitInfo->getFieldType(targetField, &valClass, targetClass); if (fieldIsStatic) { emit_initclass(targetClass); } OpType fieldType = createOpType(jitType, valClass ); OpType type; #if !defined(FJIT_NO_VALIDATION) // Initialize the type correctly getting additional information for managed pointers and objects if ( fieldType.enum_() == typeByRef ) { _ASSERTE(valClass != NULL); CORINFO_CLASS_HANDLE childClassHandle; CorInfoType childType = jitInfo->getChildType(valClass, &childClassHandle); fieldType.setTarget(OpType(childType).enum_(),childClassHandle); } else if ( fieldType.enum_() == typeRef ) VALIDITY_CHECK( valClass != NULL ); // Verify that the correct type of the instruction is used VALIDITY_CHECK( fieldIsStatic || (opcode == CEE_LDFLD) ); CORINFO_CLASS_HANDLE instanceClassHnd = jitInfo->getMethodClass(methodInfo->ftn); //INDEBUG(printf( "Field Type [%d, %d] %d \n",fieldType.enum_(),fieldType.cls(),valClass );) #endif if (opcode == CEE_LDFLD) { // There must be an object on the stack CHECK_STACK(1); type = topOp(); if (type.type_enum == typeR4 || type.type_enum == typeR8) { return FJIT_OK; } // The object on the stack can be managed pointer, object, native int, instance of object VALIDITY_CHECK( type.isPtr() || type.enum_() == typeValClass ); // Verification doesn't allow native int to be used VERIFICATION_CHECK( type.enum_() != typeI || (type.cls() && isPrimitiveValueType(type.cls())) ); // Store the object reference for the access check instanceClassHnd = type.cls(); OpType targetType = createOpType(type.enum_(), targetClass ); // Check that the object on the stack encloses the field VERIFICATION_CHECK( canAssign( jitInfo, methodInfo->ftn, type, targetType)); // Remove the instance object of the IL stack POP_STACK(1); if (fieldIsStatic) { // we don't need this pointer if (type.isValClass()) { unsigned sizeValClass = typeSizeInSlots(jitInfo, type.cls()) * sizeof(void*); emit_drop(BYTE_ALIGNED(sizeValClass)); } else { emit_POP_PTR(); } } else { //INDEBUG(printf( "Object Type [%d, %d] \n",type.enum_(),type.cls() );) if (type.isValClass() || (type.enum_() == typeI && type.cls() && isPrimitiveValueType(type.cls())) ) { // the object itself is a value class pushOp(type); // we are going to leave it on the stack emit_getSP(STACK_BUFFER); // push pointer to object } } |
As one can see, the function is using many Op methods which handle the MSIL stack (internally called operand stack). Here are some of these inline methods:
| inline OpType& FJit::topOp(unsigned back) { _ASSERTE (opStack_len > back); if ( opStack_len <= back ) RaiseException(SEH_JIT_REFUSED,EXCEPTION_NONCONTINUABLE,0,NULL); return(opStack[opStack_len-back-1]); } inline void FJit::popOp(unsigned cnt) { _ASSERTE (opStack_len >= cnt); opStack_len -= cnt; #ifdef _DEBUG opStack[opStack_len] = OpType(typeError); #endif } inline void FJit::pushOp(OpType type) { _ASSERTE (opStack_len < opStack_size); _ASSERTE (type.isValClass() || (type.enum_() >= typeI4 || type.enum_() < typeU1)); _ASSERTE (type.enum_() != 0 ); opStack[opStack_len++] = type; #ifdef _DEBUG opStack[opStack_len] = OpType(typeError); #endif } inline void FJit::resetOpStack() { opStack_len = 0; #ifdef _DEBUG opStack[opStack_len] = OpType(typeError); #endif } inline bool FJit::isOpStackEmpty() { return (opStack_len == 0); } |
The opStack is nothing else than a pointer that points to an array of OpType classes. What follows is the declaration of the OpType class along with the types it can represent:
| enum OpTypeEnum { typeError = 0, typeByRef = 1, typeRef = 2, typeU1 = 3, typeU2 = 4, typeI1 = 5, typeI2 = 6, typeI4 = 7, typeI8 = 8, typeR4 = 9, typeR8 = 10, typeRefAny = 11, typeValClass = 12, typeMethod = 13, typeCount = 14, typeI = typeI4, }; struct OpType { OpType(); OpType(OpTypeEnum opEnum); explicit OpType(CORINFO_CLASS_HANDLE valClassHandle); explicit OpType(CORINFO_METHOD_HANDLE mHandle); explicit OpType(OpTypeEnum opEnum, CORINFO_CLASS_HANDLE valClassHandle, bool setClassHandle = false, bool isReadOnly = false); explicit OpType(OpTypeEnum opEnum, OpTypeEnum childEnum); explicit OpType(CorInfoType jitType, CORINFO_CLASS_HANDLE valClassHandle, bool setClassHandle = false); explicit OpType(CorInfoType jitType); static const char toOpStackType[]; /* OPERATORS */ int operator==(const OpType& opType) { return( type_handle == opType.type_handle && type_enum == opType.type_enum && readonly == opType.readonly ); } int operator!=(const OpType& opType) { return(!(*this == opType)); } /* ACCESSORS */ bool isPtr() { return(type_enum == typeRef || type_enum == typeByRef || type_enum == typeI ); } bool isPrimitive() { return((unsigned) type_enum <= (unsigned) typeRefAny); } // refany is a primitive bool isValClass() { return((unsigned) type_enum >= (unsigned) typeRefAny); } // refany is a valclass too bool isTargetPrimitive() { return((unsigned) child_type <= (unsigned) typeRefAny); } inline bool isNull() { return (child_type == typeRef && type_enum == typeRef); } inline bool isRef() { return (type_enum == typeRef); } inline bool isRefAny() { return (type_enum == typeRefAny); } inline bool isByRef() { return (type_enum == typeByRef); } inline bool isReadOnly() { return (readonly == 1); } inline bool isMethod() { return (type_enum == typeMethod); } inline OpTypeEnum enum_() { return ( type_enum ); } inline CORINFO_CLASS_HANDLE cls() { return ( type_handle ); } inline CORINFO_METHOD_HANDLE getMethod() { return ( method_handle ); } inline OpTypeEnum targetAsEnum() { return child_type; } OpType getTarget() { return ( isTargetPrimitive() ? OpType( child_type ) : OpType( type_handle )); } bool matchTarget( OpType other ) { _ASSERTE( type_enum == typeByRef ); return isTargetPrimitive() ? other.enum_() == targetAsEnum() : other.cls() == cls(); } /* MUTATORS */ // unsafe, please limit use void fromInt(unsigned i){ type_handle = (CORINFO_CLASS_HANDLE)(size_t)i; } void setHandle(CORINFO_CLASS_HANDLE h) { type_handle = h; } void setTarget( OpTypeEnum opEnum, CORINFO_CLASS_HANDLE h ) { if ( h == NULL ) child_type = opEnum; else type_handle = h; _ASSERTE( (child_type != typeByRef && child_type != typeRef) || isNull() );} void setTarget( CorInfoType jitType, CORINFO_CLASS_HANDLE h ) { if ( h == NULL ) child_type = OpType(jitType).enum_(); else type_handle = h; _ASSERTE( (child_type != typeByRef && child_type != typeRef) || isNull() );} void setReadOnly(bool isReadOnly) { readonly = (unsigned) isReadOnly; } void init(OpTypeEnum opEnum, CORINFO_CLASS_HANDLE valClassHandle, bool isReadOnly = false ) { type_enum = opEnum; type_handle = valClassHandle; readonly = (unsigned) isReadOnly; } void init(CorInfoType jitType, CORINFO_CLASS_HANDLE valClassHandle ) { type_enum = OpType(jitType).enum_(); type_handle = valClassHandle; } static const OpTypeEnum Signed[]; void toSigned() { if (type_enum < typeI1) type_enum = Signed[type_enum]; } static const OpTypeEnum Normalize[]; void toNormalizedType() { if (type_enum < typeI4) type_enum = Normalize[type_enum]; } static const OpTypeEnum FPNormalize[]; void toFPNormalizedType() { if ( type_enum < typeR8) type_enum = FPNormalize[type_enum]; } // Data structure unsigned readonly : 1; OpTypeEnum type_enum : 31; union { // Valid only for STRUCT or REF or BYREF CORINFO_CLASS_HANDLE type_handle; // Valid only for type METHOD CORINFO_METHOD_HANDLE method_handle; // Valid for BYREF to primitives only OpTypeEnum child_type; }; }; |
The actual data contained in this class fits into a qword. The main value of this class is the type member. In some cases (depending on the type), additional information, such as a handle, is needed. For instance, if the type is typeMethod, a CORINFO_METHOD_HANDLE is also needed. The reason why I pasted this code is that understanding the MSIL stack might turn useful for the next two paragraphs.
This topic has never been discussed yet regarding the .NET context. What I mean by native decompiling is not going from machine code to C# (to name one), but going from machine code to MSIL. The MSIL can then be decompiled into C#. Converting machine code to MSIL is not only easier, but the only logical decompiling method. This procedure is difficult: I'm only discussing the possibility. The most important thing is stack interpretation. Let's take for instance part of the code seen in the Native Injection paragraph:
| 00000011 mov edx, [0x238b9bc] 00000017 mov ecx, eax 00000019 call 0x7426edd0 0000001E and eax, 0xff 00000023 jz 0x2c 00000025 mov eax, 0x1 0000002A jmp 0x2e 0000002C xor eax, eax 0000002E test eax, eax 00000030 jz 0x42 00000032 mov ecx, [0x238b9c0] 00000038 call [0x5102544] 0000003E pop esi 0000003F ret 0x4 00000042 mov ecx, [0x238b9c4] 00000048 call [0x5102544] 0000004E pop esi 0000004F ret 0x4 |
Since I know that the call at offset 38h calls as MessageBox.Show(String), I also know that the first argument on the stack or in this case, since it's a fastcall, the data in ecx represents a String class. However, this is rather normal, because MessageBox is a public API. Public APIs could be solved in the same way in native C++ applications. The difference can be noted when considering the CheckPassword(String) method called in this code. CheckPassword is a private method, nonetheless I can retrieve its arguments, its return type and, if it hasn't been obfuscated, even its name. Thus, I perfectly know that the data moved in ecx represents an instance, since CheckPassword is a non-static class member, and that the data moved in edx represents a String class. I also know that this call returns a boolean value and can interpret the instructions below accordingly.
I have to do a small comparision with native C++ applications, because many people minimize the fact that MSIL code can be decompiled by saying that even C/C++ code can be decompiled. This is a completely incorrect statement as it compares apples to oranges. Speaking about C/C++ applications, a rough decompiled C code can be obtained sometimes. In some cases, the decompiler is not even able to generate any C code at all. And even if he is able to, in many cases the decompiled code is wrong. And even in those cases where the decompiled C code is actually right (meaning it correctly represents what the machine code is doing), it is not guaranteed to be easier to understand for the reader than the machine code, since the decompiled C code is mostly a mess. And last but not least, the C decompiler has no clue of how to interpret data. For example, when I'm referencing a member in a structure, the resulting decompiled C code will only produce a reference to pointer + N, where N is the offset to the referenced member. This means that "info.bValue = TRUE" generates something like "*((int *) (ptr + N)) = 1;" in C code. The same applies to the method's arguments, return value, calls, etc. Although the decompiled C code may sometimes be recompilable, it is absolutely no threat to intellectual property. At least, no more than analyzing the machine code is.
When talking about protecting .NET applications, the root of the problem is the MetaData. The MetaData is useful for many purposes, but I'm analyzing it from the point of view of a reverser. The MetaData leaves nothing uncovered, making it impossible to hide something.
Although .NET native decompiling hasn't to be thought as an important issue right now, it's interesting to evaluate the possibility, since it would make an attempt such as a Native Framework Deployment service useless. Native images themselves have to hold enough information in order for the execution engine to solve the references within the native code. This information could be exploited by a reverser for decompiling. Even if the information was missing, like in the case when one manually injects native code, it would be still possible (although not easy) to communicate with the JIT to solve the references.
The machine code could, in theory, also be obfuscated in order to further complicate decompiling, but it would be still possible to solve the references in the code, making it much easier to understand it than its C/C++ equivalent.
Virtual machines have been a big hit in the area of native code. It was only a matter of time, before someone tried to bring the concept to .NET code. I don't know how many protections rely on this technology, but I can say that Microsoft itself invested in it with its SLP (Software Licensing & Protection) services. I can't analyze the code of their product as it would in some way violate their licensing terms, but I can discuss it.
SLP provides a per method protection. This means the user can choose which methods to protect. A protected method when disassembled looks like this:
| private bool CheckPassword(string strPass) { object[] args = new object[] { strPass }; return (bool) SLMRuntime.SVMExecMethod(this, "28d981d5a74646a9bed4c66fdcbd82d8", args); } |
The method does nothing else than invoking the virtual machine by passing the class instance, the method's arguments and a string that represents the method being called.
The protection's runtime is made of three .NET assemblies. The runtime creates its own virtual machine on top of the .NET framework. .NET virtual machines use the reflection to solve external references. If I reference a private variable inside, let's say, the current class, the virtual machine will do the following:
| using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Text; using System.Windows.Forms; using System.Reflection; namespace reflection { public partial class Form1 : Form { public Form1() { InitializeComponent(); } private int MyPrivateVariable = 0; private void ChangePrivateVar(object obj) { Type t = obj.GetType(); // get the field, no matter how the field is declared FieldInfo f = t.GetField("MyPrivateVariable", BindingFlags.Public | BindingFlags.Static | BindingFlags.NonPublic | BindingFlags.Instance); f.SetValue(obj, (int) 1); } private void button1_Click(object sender, EventArgs e) { // displays 0 MessageBox.Show(MyPrivateVariable.ToString()); // changes the value given the current object ChangePrivateVar(this); // displays 1 MessageBox.Show(MyPrivateVariable.ToString()); } } } |
As one can see, MetaData turns out to be quite useful when combined with reflection. However, I leave the reader imagine how slow a .NET virtual machine built on top of the reflection technology will result in execution time. That's why even the SLP guide warns its users:
In the earlier analogy about baking a cake from a recipe, it was assumed that you had to protect the entire recipe. Of course, there is a lot of similarity between cake recipes, and it is unnecessary to protect the entire recipe, just those parts of it that make it unique. This would do little to reduce the security of the recipe, but makes it much faster to read–only those secret ingredients need to be decrypted.
Similarly, because the SVM needs to interpret the SVML code, and runs on top of the CLR, there is a performance element to the equation that needs to be addressed. You do not want to protect the entire code base, because it would slow the whole application down and add little to overall security. Instead, you want to protect only what is necessary: the secret ingredient.
In this text, they make it sound like it is something good that only few methods are being protected, though this isn't realistic. Given that the .NET virtual machine approach is quite good and that it is much more professional than Native Framework Deployment services, it has some signifcant flaws. This approach might be the best one regarding the licensing of a .NET application, but it really can't help much to protect intellectual property. If one's entire application relies on a bunch of non execution-time critical methods, then what it is hiding really isn't a great secret anyway. There are also some restrictions regarding the virtualization of methods:
Methods with the following constructs cannot be transformed in Code Protector.
- Methods within generic classes.
- Methods containing explicit instantiations of generic types.
- Methods with generic parameters.
- Non-static methods of a structure.
- Methods with “out” or “ref” parameters.
- Methods that invoke other methods with “out” or “ref” parameters.
- Methods that modify any method parameter, even if the parameter is defined as
a “by value”.
- Methods with a variable number of parameters (e.g., using the “params” keyword
in C#).
- Methods with too many local variables or parameters (> 254).
- Methods that contain calls to Reflection.Assembly.GetExecutingAssembly(),
Reflection.MethodInfo.GetCurrentMethod(), or
Reflection.Assembly.GetCallingAssembly().
- CLR 1.1 Framework only: Methods that create objects using constructors that
have a variable number of parameters. This restriction does not exist when a
non-constructor method is invoked.
- Implicit and explicit cast operators cannot be transformed to the Secure
Virtual Machine (SVM).
- Unsafe code – For example, in C#, methods that contain the keyword unsafe
typically cannot be transformed.
This list is also interesting for those who might consider writing a .NET virtual machine themselves. I have given the reader my opinion about this protection technique, but let's examine how one could overcome it.
If one is really interested in what a protected method does, it is necessary to analyze the virtual machine's code. The first approach which comes to my mind is using the .NET profiling API to inject logging code in order to retrieve the methods called inside the virtual machine. This would provide an execution flow log which can be used to analyze the virtual machine's code executed for a particular method.
The second tecnique to overcome this kind of protection is based on substitution. If one isn't interested in what the code does, since he knows it or knows what the code should do, then he can replace the code with his own. This can be easily accomplished through Sebastien Lebreton's Reflexil. This approach addresses cracking, not reversing. But since SLP is also a licensing system, this must be taken into account. Let's say that the method F sets up the inizializations settings for an application. This method is protected through SLP, which won't execute it unless one has a valid license for the program. One could reimplement the F method and completely detach the SLP runtime from the protected assembly. This might be difficult in some cases, but that's what reversing is all about. However, SLP is terribly slow and protecting many methods reflects in an unacceptable performance loss. The performance problem could be signifcantly improved by automatically generating native images during the setup process.
Sometimes, the virtual machine protection is combined with code obfuscation to provide security for all the methods which have not being virtualized. In this case, if one is interested in decompiling the MSIL code, the first step is removing the code obfuscation. This can only be done by analyzing the obfuscation algorithm and understanding how to reverse it. The rebuilding of the de-obfuscated assembly can be easily achieved through Rebel.NET.
As I've never read a book nor an article about the CLR infrastructure, what has been presented in this article are the .NET internals from the perspective of a reverser. This was the second part of the two series of articles about .NET internals and protections. I hope I have given the reader an idea of the problems surrounding .NET protection systems. As the .NET technology is still very young, it might change significantly. I don't know if intellectual property will be taken into account in next versions of the framework. I also hope that these problems will be taken into account when new frameworks are going to be developed in the future. As the .NET framework has been a new playground for reversing, I can only guess that many problems were not too obvious at beginning of its development (although the Java experience should've been a lesson). A possible evolution of the .NET framework could rely on offering native compiling as alternative to MSIL and drastically reducing the MetaData information by preserving it only for public types / members.
Maybe, I'm totally wrong and we will soon see most major applications being deployed as MSIL assemblies. I strongly doubt it.
Daniel Pistelli