I'm writing this document because I need to express myself about this subject. Despite the fact that C++ is one of the most used programming languages, especially for serious projects, it gets much criticism for being messy, bloated, complicate etc. I believe these critics miss the point. Yes, C++ is a very powerful programming language and that's why it is difficult. And this is also why sometimes C++ source codes are poorly written. I don't believe in improvements of C++ resulting in a new programming language. All attempts in that direction have failed. I think that C++ is here to stay for many reasons. Not only because of the amount of code already available in C++, but also because at the moment there isn't a better programming language for large projects. The only thing I want is for C++ to evolve, but not by losing compatibility with older code or by removing some features. No, I'd like C++ to evolve in a healthy and compatible way. This paper contains the suggestions to achieve this and I will demonstrate technically how it can be implemented at low level.
Everybody should be warned that the material contained in this paper is purely theoretical. The first idea behind this paper came out while working on a particular project. At the time I discovered myself in need of particular dynamic features. So, for many months I had some ideas in the background of my mind and decided eventually to write them down. So, in this paper I'm going to talk about the current status of dynamism for C++, why dynamism is important and what could be done. At the time of writing (November 2008) the new C++0x (or C++09) standard has not yet been introduced. However, I will talk about it throughout this paper when the related topic is affected by it.
The only serious C++ framework I've seen around is the Qt framework. Qt
brought C++ to a new level. While the signals and slots technology
introduced by Qt is very original, what really was interesting in the whole
idea was that an object could call other object methods regardless of the
object declaration. In order for signals and slots to work, dynamism was brought
into C++. Well, of course, when using only signals and slots, the developer
doesn't directly notice this behavior, it's all handled by the framework.
However, this dynamism can be used by the developer through the QMetaObject
class as well.
I'm not going to explain the basics of signals and slots. The reader might check out the Qt documentation page. What I will do is to breifly show the internal workings of Qt dynamism. The current version of the Qt framework at the time I'm writing this paper is 4.4.3.
Let's consider a simple signals and slots example:
// sas.h
#include <QObject>
class Counter : public QObject
{
Q_OBJECT
public:
Counter() { m_value = 0; };
int value() const { return m_value; };
public slots:
void setValue(int value)
{
if (value != m_value)
{
m_value = value;
emit valueChanged(value);
}
};
signals:
void valueChanged(int newValue);
private:
int m_value;
};
// main.cpp
#include "sas.h"
int main(int argc, char *argv[])
{
Counter a, b;
QObject::connect(&a, SIGNAL(valueChanged(int)),
&b, SLOT(setValue(int)));
a.setValue(12); // a.value() == 12, b.value() == 12
b.setValue(48); // a.value() == 12, b.value() == 48
return 0;
}
The SIGNAL and SLOT macro enclose their content in brackets, making it
a string. Well, they do one more thing. They put an identification number in the
string:
#define SLOT(a) "1"#a
#define SIGNAL(a) "2"#a
So, one might as well write:
QObject::connect(&a, "2valueChanged(int)", &b, "1setValue(int)");
The Qt keywords signals and slots, which can be found in the class
header, are only useful to the Qt metacompiler (the moc).
# if defined(QT_NO_KEYWORDS)
# define QT_NO_EMIT
# else
# define slots
# define signals protected
# endif
# define Q_SLOTS
# define Q_SIGNALS protected
# define Q_PRIVATE_SLOT(d, signature)
# define Q_EMIT
#ifndef QT_NO_EMIT
# define emit
#endif
In fact, as you can see, even the emit macro just increases readability. Only
the signals macro is a bit different, because it qualifies Qt signals as
protected methods, whereas slots can be of any kind. The first interesting part
is the Q_OBJECT macro:
/* tmake ignore Q_OBJECT */
#define Q_OBJECT_CHECK \
template <typename T> inline void qt_check_for_QOBJECT_macro(const T &_q_argument)
const \
{ int i = qYouForgotTheQ_OBJECT_Macro(this, &_q_argument); i = i; }
template <typename T>
inline int qYouForgotTheQ_OBJECT_Macro(T, T) { return 0; }
template <typename T1, typename T2>
inline void qYouForgotTheQ_OBJECT_Macro(T1, T2) {}
#endif // QT_NO_MEMBER_TEMPLATES
/* tmake ignore Q_OBJECT */
#define Q_OBJECT \
public: \
Q_OBJECT_CHECK \
static const QMetaObject staticMetaObject; \
virtual const QMetaObject *metaObject() const; \
virtual void *qt_metacast(const char *); \
QT_TR_FUNCTIONS \
virtual int qt_metacall(QMetaObject::Call, int, void **); \
private:
staticMetaObject is the QMetaObject, which is static because, being the
metadata class, it's shared by all instances of the same class. The metaObject
method just returns staticMetaObject. QT_TR_FUNCTIONS is a macro that defines
all tr functions, used for multi-language support. qt_metacast performs a dynamic cast,
given the class name or the name of one of its base classes (Qt doesn't rely on
RTTI, obviously). qt_metacall calls
an internal signal or slot by its index. Before I'm going to discuss the code
generated by the moc, here's the QMetaObject declaration:
struct Q_CORE_EXPORT QMetaObject
{
const char *className() const;
const QMetaObject *superClass() const;
QObject *cast(QObject *obj) const;
#ifndef QT_NO_TRANSLATION
// ### Qt 4: Merge overloads
QString tr(const char *s, const char *c) const;
QString trUtf8(const char *s, const char *c) const;
QString tr(const char *s, const char *c, int n) const;
QString trUtf8(const char *s, const char *c, int n) const;
#endif // QT_NO_TRANSLATION
int methodOffset() const;
int enumeratorOffset() const;
int propertyOffset() const;
int classInfoOffset() const;
int methodCount() const;
int enumeratorCount() const;
int propertyCount() const;
int classInfoCount() const;
int indexOfMethod(const char *method) const;
int indexOfSignal(const char *signal) const;
int indexOfSlot(const char *slot) const;
int indexOfEnumerator(const char *name) const;
int indexOfProperty(const char *name) const;
int indexOfClassInfo(const char *name) const;
QMetaMethod method(int index) const;
QMetaEnum enumerator(int index) const;
QMetaProperty property(int index) const;
QMetaClassInfo classInfo(int index) const;
QMetaProperty userProperty() const;
static bool checkConnectArgs(const char *signal, const char *method);
static QByteArray normalizedSignature(const char *method);
static QByteArray normalizedType(const char *type);
// internal index-based connect
static bool connect(const QObject *sender, int signal_index,
const QObject *receiver, int method_index,
int type = 0, int *types = 0);
// internal index-based disconnect
static bool disconnect(const QObject *sender, int signal_index,
const QObject *receiver, int method_index);
// internal slot-name based connect
static void connectSlotsByName(QObject *o);
// internal index-based signal activation
static void activate(QObject *sender, int signal_index, void **argv);
static void activate(QObject *sender, int from_signal_index, int to_signal_index, void **argv);
static void activate(QObject *sender, const QMetaObject *, int local_signal_index, void **argv);
static void activate(QObject *sender, const QMetaObject *, int from_local_signal_index,
int to_local_signal_index, void
**argv);
// internal guarded pointers
static void addGuard(QObject **ptr);
static void removeGuard(QObject **ptr);
static void changeGuard(QObject **ptr, QObject *o);
static bool invokeMethod(QObject *obj, const char *member,
Qt::ConnectionType,
QGenericReturnArgument ret,
QGenericArgument val0 = QGenericArgument(0),
QGenericArgument val1 = QGenericArgument(),
QGenericArgument val2 = QGenericArgument(),
QGenericArgument val3 = QGenericArgument(),
QGenericArgument val4 = QGenericArgument(),
QGenericArgument val5 = QGenericArgument(),
QGenericArgument val6 = QGenericArgument(),
QGenericArgument val7 = QGenericArgument(),
QGenericArgument val8 = QGenericArgument(),
QGenericArgument val9 = QGenericArgument());
// [ ... several invokeMethod overloads ...]
enum Call {
InvokeMetaMethod,
ReadProperty,
WriteProperty,
ResetProperty,
QueryPropertyDesignable,
QueryPropertyScriptable,
QueryPropertyStored,
QueryPropertyEditable,
QueryPropertyUser
};
#ifdef QT3_SUPPORT
QT3_SUPPORT const char *superClassName() const;
#endif
struct { // private data
const QMetaObject *superdata;
const char *stringdata;
const uint *data;
const QMetaObject **extradata;
} d;
};
The important part of QMetaObject is the internal d struct. The first
member of this struct is a QMetaObject class pointer. This member points to the
parent Qt object metadata class. A class like ours can inherit from more than
just one class, but it can have only one QObject (or from it derived) base
class, and that's the super class. Moreover, the moc relies on the fact that in a
QObject derived class
declaration the first inherited class is a QObject (or derived) base class.
Let's take a Qt dialog, which often uses multiple inheritance in its
implementation:
class ConvDialog : public QDialog, private Ui::ConvDialog
{
Q_OBJECT
Which makes the moc produce this code:
const QMetaObject ConvDialog::staticMetaObject = {
{ &QDialog::staticMetaObject, qt_meta_stringdata_ConvDialog,
qt_meta_data_ConvDialog, 0 }
};
But, if ConvDialog inherits Ui::ConvDialog before QDialog, the moc generates:
const QMetaObject ConvDialog::staticMetaObject = {
{ &Ui::ConvDialog::staticMetaObject, qt_meta_stringdata_ConvDialog,
qt_meta_data_ConvDialog, 0 }
};
Which is wrong, because Ui::ConvDialog is not a derived class of QObject and
thus hasn't got a staticMetaObject member. Doing so will result in a
compiling error.
The second member of the d struct is a char array, which contains the
literal metadata of the class. The third member is an unsigned int array. This
array is a table and it contains all the metadata offsets, flags etc. So, if one
wants to enumerate the slots and signals of a class, one would have to go
through this table and get the right offsets to obtain the methods names from
the stringdata array. It also references properties and enums. The fourth member is a null terminated array of
QMetaObject classes. This member provides storage for metadata information for
additional classes. I've never seen it used, but it is referenced by the
QMetaObject_findMetaObject function.
static const QMetaObject *QMetaObject_findMetaObject(const QMetaObject *self, const char *name)
{
while (self) {
if (strcmp(self->d.stringdata, name) == 0)
return self;
if (self->d.extradata) {
const QMetaObject **e = self->d.extradata;
while (*e) {
if (const QMetaObject *m =QMetaObject_findMetaObject((*e), name))
return m;
++e;
}
}
self = self->d.superdata;
}
return self;
}
This function gets called only by the property method, which, in turn, gets
called by propertyCount, propertyOffset and indexOfProperty.
And here's the moc generated code for our Counter class:
/****************************************************************************
** Meta object code from reading C++ file 'sas.h'
**
** Created: Mon 3. Nov 15:20:11 2008
** by: The Qt Meta Object Compiler version 59 (Qt 4.4.3)
**
** WARNING! All changes made in this file will be lost!
*****************************************************************************/
#include "../sas.h"
#if !defined(Q_MOC_OUTPUT_REVISION)
#error "The header file 'sas.h' doesn't include <QObject>."
#elif Q_MOC_OUTPUT_REVISION != 59
#error "This file was generated using the moc from 4.4.3. It"
#error "cannot be used with the include files from this version of Qt."
#error "(The moc has changed too much.)"
#endif
QT_BEGIN_MOC_NAMESPACE
static const uint qt_meta_data_Counter[] = {
// content:
1, // revision
0, // classname
0, 0, // classinfo
2, 10, // methods
0, 0, // properties
0, 0, // enums/sets
// signals: signature, parameters, type, tag, flags
18, 9, 8, 8, 0x05,
// slots: signature, parameters, type, tag, flags
42, 36, 8, 8, 0x0a,
0 // eod
};
static const char qt_meta_stringdata_Counter[] = {
"Counter\0\0newValue\0valueChanged(int)\0"
"value\0setValue(int)\0"
};
const QMetaObject Counter::staticMetaObject = {
{ &QObject::staticMetaObject, qt_meta_stringdata_Counter,
qt_meta_data_Counter, 0 }
};
const QMetaObject *Counter::metaObject() const
{
return &staticMetaObject;
}
void *Counter::qt_metacast(const char *_clname)
{
if (!_clname) return 0;
if (!strcmp(_clname, qt_meta_stringdata_Counter))
return static_cast<void*>(const_cast< Counter*>(this));
return QObject::qt_metacast(_clname);
}
int Counter::qt_metacall(QMetaObject::Call _c, int _id, void **_a)
{
_id = QObject::qt_metacall(_c, _id, _a);
if (_id < 0)
return _id;
if (_c == QMetaObject::InvokeMetaMethod) {
switch (_id) {
case 0: valueChanged((*reinterpret_cast< int(*)>(_a[1]))); break;
case 1: setValue((*reinterpret_cast< int(*)>(_a[1]))); break;
}
_id -= 2;
}
return _id;
}
// SIGNAL 0
void Counter::valueChanged(int _t1)
{
void *_a[] = { 0, const_cast<void*>(reinterpret_cast<const void>(&_t1)) };
QMetaObject::activate(this, &staticMetaObject, 0, _a);
}
QT_END_MOC_NAMESPACE
The qt_metacall method calls other internal methods of the class by their
index. Qt dynamism relies on indexes, avoiding pointers. The job of actually
calling methods is left to the compiler. This implementation makes the signals
and slots mechanism quite fast and I'll show later why.
Arguments are passed through a pointer to pointer array and casted appropriately when calling the method. Using pointers, of course, is the only way to put all kinds of types in an array. Arguments start from position 1, because position 0 is reserved for the data to return. The signals and slots in the example are declared void and, thus, have no data to return. If a slot had data to return, the code contained in the switch would look like this:
if (_c == QMetaObject::InvokeMetaMethod) {
switch (_id) {
case 0: valueChanged((*reinterpret_cast< int(*)>(_a[1]))); break;
case 1: setValue((*reinterpret_cast< int(*)>(_a[1]))); break;
case 2: { int _r = exampleMethod((*reinterpret_cast< int(*)>(_a[1])));
if (_a[0]) *reinterpret_cast< int*>(_a[0]) = _r; } break;
}
The other interesting method generated by the moc is valueChanged, which
represents the code executed to emit the valueChanged signal. This code calls
the activate method of QMetaObject, which is just an overload of this activate
method:
void QMetaObject::activate(QObject *sender, int from_signal_index, int to_signal_index, void **argv)
{
// [... other code ...]
// emit signals in the following order: from_signal_index <= signals <= to_signal_index, signal < 0
for (int signal = from_signal_index;
(signal >= from_signal_index && signal <= to_signal_index) || (signal == -2);
(signal == to_signal_index ? signal = -2 : ++signal))
{
if (signal >= connectionLists->count()) {
signal = to_signal_index;
continue;
}
const QObjectPrivate::ConnectionList &connectionList = connectionLists->at(signal);
int count = connectionList.count();
for (int i = 0; i < count; ++i) {
const QObjectPrivate::Connection *c = &connectionList[i];
if (!c->receiver)
continue;
QObject * const receiver = c->receiver;
// determine if this connection should be sent immediately or
// put into the event queue
if ((c->connectionType == Qt::AutoConnection
&& (currentThreadData != sender->d_func()->threadData
|| receiver->d_func()->threadData != sender->d_func()->threadData))
|| (c->connectionType == Qt::QueuedConnection)) {
queued_activate(sender, signal, *c, argv);
continue;
} else if (c->connectionType == Qt::BlockingQueuedConnection) {
blocking_activate(sender, signal, *c, argv);
continue;
}
const int method = c->method;
QObjectPrivate::Sender currentSender;
currentSender.sender = sender;
currentSender.signal = signal < 0 ? from_signal_index : signal;
QObjectPrivate::Sender * const previousSender =
QObjectPrivate::setCurrentSender(receiver, ¤tSender);
locker.unlock();
if (qt_signal_spy_callback_set.slot_begin_callback != 0) {
qt_signal_spy_callback_set.slot_begin_callback(receiver,
method,
argv ? argv : empty_argv);
}
#if defined(QT_NO_EXCEPTIONS)
receiver->qt_metacall(QMetaObject::InvokeMetaMethod, method, argv ? argv : empty_argv);
#else
try {
receiver->qt_metacall(QMetaObject::InvokeMetaMethod, method, argv ? argv : empty_argv);
} catch (...) {
locker.relock();
QObjectPrivate::resetCurrentSender(receiver, ¤tSender, previousSender);
--connectionLists->inUse;
Q_ASSERT(connectionLists->inUse >= 0);
if (connectionLists->orphaned && !connectionLists->inUse)
delete connectionLists;
throw;
}
#endif
locker.relock();
if (qt_signal_spy_callback_set.slot_end_callback != 0)
qt_signal_spy_callback_set.slot_end_callback(receiver, method);
QObjectPrivate::resetCurrentSender(receiver, ¤tSender, previousSender);
if (connectionLists->orphaned)
break;
}
if (connectionLists->orphaned)
break;
}
--connectionLists->inUse;
Q_ASSERT(connectionLists->inUse >= 0);
if (connectionLists->orphaned && !connectionLists->inUse)
delete connectionLists;
locker.unlock();
if (qt_signal_spy_callback_set.signal_end_callback != 0)
qt_signal_spy_callback_set.signal_end_callback(sender, from_signal_index);
}
This method does lots of stuff, including checking whether the current
connection should be processed immediately or put into the event queue. If so,
it calls the appropriate activate method variant and then continues with the
next connection in the ConnectionList. Otherwise, if the connection should be
processed immediately, the id of the method to call is retrived from the current
connection and the qt_metacall method of the receiver gets called. To simplify the
execution flow:
const QObjectPrivate::ConnectionList &connectionList = connectionLists->at(signal);
int count = connectionList.count();
for (int i = 0; i < count; ++i) {
const QObjectPrivate::Connection *c = &connectionList[i];
QObject * const receiver = c->receiver;
const int method = c->method;
receiver->qt_metacall(QMetaObject::InvokeMetaMethod, method, argv ? argv : empty_argv);
And this tells us all we need to know about the internals of signals and
slots. When calling the connect function, the signal and slot signatures
are converted to their ids, which are then stored in the Connection class.
Everytime a signal is emitted, the connections for the signal's id are retrieved
and their slots are called by their ids.
The last part which needs to be discussed are dynamic invokes. The
QMetaObject class offers the invokeMethod method to dinamically call a method.
This method is a bit different than signals and slots, because it needs to build
a signature for the method to call from its return type, name and arguments
types, and then look up the metadata to retrieve its id, before calling the
qt_metacall method of the object.
bool QMetaObject::invokeMethod(QObject *obj, const char *member, Qt::ConnectionType type,
QGenericReturnArgument ret,
QGenericArgument val0,
QGenericArgument val1,
QGenericArgument val2,
QGenericArgument val3,
QGenericArgument val4,
QGenericArgument val5,
QGenericArgument val6,
QGenericArgument val7,
QGenericArgument val8,
QGenericArgument val9)
{
if (!obj)
return false;
QVarLengthArray<char, 512> sig;
int len = qstrlen(member);
if (len <= 0)
return false;
sig.append(member, len);
sig.append('(');
enum { MaximumParamCount = 11 };
const char *typeNames[] = {ret.name(), val0.name(), val1.name(), val2.name(), val3.name(),
val4.name(), val5.name(), val6.name(), val7.name(), val8.name(),
val9.name()};
int paramCount;
for (paramCount = 1; paramCount < MaximumParamCount; ++paramCount) {
len = qstrlen(typeNames[paramCount]);
if (len <= 0)
break;
sig.append(typeNames[paramCount], len);
sig.append(',');
}
if (paramCount == 1)
sig.append(')'); // no parameters
else
sig[sig.size() - 1] = ')';
sig.append('\0');
int idx = obj->metaObject()->indexOfMethod(sig.constData());
if (idx < 0) {
QByteArray norm = QMetaObject::normalizedSignature(sig.constData());
idx = obj->metaObject()->indexOfMethod(norm.constData());
}
if (idx < 0)
return false;
// check return type
if (ret.data()) {
const char *retType = obj->metaObject()->method(idx).typeName();
if (qstrcmp(ret.name(), retType) != 0) {
// normalize the return value as well
// the trick here is to make a function signature out of the return type
// so that we can call normalizedSignature() and avoid duplicating code
QByteArray unnormalized;
int len = qstrlen(ret.name());
unnormalized.reserve(len + 3);
unnormalized = "_("; // the function is called "_"
unnormalized.append(ret.name());
unnormalized.append(')');
QByteArray normalized = QMetaObject::normalizedSignature(unnormalized.constData());
normalized.truncate(normalized.length() - 1); // drop the ending ')'
if (qstrcmp(normalized.constData() + 2, retType) != 0)
return false;
}
}
void *param[] = {ret.data(), val0.data(), val1.data(), val2.data(), val3.data(), val4.data(),
val5.data(), val6.data(), val7.data(), val8.data(), val9.data()};
if (type == Qt::AutoConnection) {
type = QThread::currentThread() == obj->thread()
? Qt::DirectConnection
: Qt::QueuedConnection;
}
if (type == Qt::DirectConnection) {
return obj->qt_metacall(QMetaObject::InvokeMetaMethod, idx, param) < 0;
} else {
if (ret.data()) {
qWarning("QMetaObject::invokeMethod: Unable to invoke methods with return values in queued "
"connections");
return false;
}
int nargs = 1; // include return type
void **args = (void **) qMalloc(paramCount * sizeof(void *));
int *types = (int *) qMalloc(paramCount * sizeof(int));
types[0] = 0; // return type
args[0] = 0;
for (int i = 1; i < paramCount; ++i) {
types[i] = QMetaType::type(typeNames[i]);
if (types[i]) {
args[i] = QMetaType::construct(types[i], param[i]);
++nargs;
} else if (param[i]) {
qWarning("QMetaObject::invokeMethod: Unable to handle unregistered datatype '%s'",
typeNames[i]);
for (int x = 1; x < i; ++x) {
if (types[x] && args[x])
QMetaType::destroy(types[x], args[x]);
}
qFree(types);
qFree(args);
return false;
}
}
if (type == Qt::QueuedConnection) {
QCoreApplication::postEvent(obj, new QMetaCallEvent(idx, 0, -1, nargs, types, args));
} else {
if (QThread::currentThread() == obj->thread()) {
qWarning("QMetaObject::invokeMethod: Dead lock detected in BlockingQueuedConnection: "
"Receiver is %s(%p)",
obj->metaObject()->className(), obj);
}
// blocking queued connection
#ifdef QT_NO_THREAD
QCoreApplication::postEvent(obj, new QMetaCallEvent(idx, 0, -1, nargs, types, args));
#else
QSemaphore semaphore;
QCoreApplication::postEvent(obj, new QMetaCallEvent(idx, 0, -1, nargs, types, args, &semaphore));
semaphore.acquire();
#endif // QT_NO_THREAD
}
}
return true;
}
The method id is retrieved through indexOfMethod. If the method signature
can't be found, invokeMethod returns false. And that's all I wanted to show
about Qt dynamism. I'm not showing how properties are handled, because it all
adds up to the same thing and showing it would be redundant. However, if you're
interested in Qt internals, you can read
this article.
I wrote this paragraph about the Qt framework to show the C++ dynamism available at the moment. In my opinion Qt is the best framework around, and not just in terms of C++. The people who created Qt recognized immediately that, in order to create a solid GUI development environment, dynamism had to be brought into C++, and the benefits of this dynamism affected not only GUIs but the entire framework. However, the high level implementation of dynamism in Qt suffers from the current limits of C++, meaning that the idea could be brought to a whole new level; and it isn't as fast as it could be either. Anyone can understand that going through a switch block and using a pointer to pointer array for every slot being called when a signal is emitted isn't as fast as calling a method directly. Although dynamism always brings an overhead to execution time, a compiler implementation makes it possible to re-think the concept.
For one, it's essential to create GUI frameworks like Qt did. New frameworks
heavily rely on dynamism. Think about Cocoa and Objective-C. But there are other
reasons. For instance, it's very easy to integrate a scripting language in Qt.
Using the QMetaObject class you can call any method that has its signature
stored. So, regular method per method exposing isn't necessary.
However, even if Qt hugely increases C++ power, it cannot overcome some of the limits imposed by the language. For instance:
class B
{
int x, y;
};
class A : public B
{
int z;
};
Let's say that the code of B is
located in an external module. If I add a member to B in the external module, I have to recompile the main application with the changed
class declaration as well. This is, of course, logical since the members are
directly mapped to memory in the declaration order and are retrieved by absolute
position. The memory layout of A is: x, y, z. This means that the
position of the z member is given by the this pointer of the class
incremented by eight (which is the size of B). If I add a member to B and
recompile the external module and not the main application, it will result in
corrupted code. This problem which afflicts C++ classes is commonly called Fragile Binary Interface (FBI) and
Fragile Base Class (FBC) problem. The introduction of dynamism can completely
overcome FBC problems. This topic will be discussed in the paragraph about
inheritance.
So, to sum up, dynamism brings several advantages, some of these are:
1) More abstraction (no FBC).
2) Easy framework development.
3) Easy scripting language integration.
4) Independent external objects.
5) Generic compiled code (discussed later).
6) Faster compiling (discussed later).
7) Less ugly C++ hacks.
This is only a brief list of fundamental concepts. Some of these concepts will be explained later.
I have absolutely no intention of forcing dynamism, removing features or
breaking existing code compatibility. My main proposition is to introduce a
new keyword: dynamic. This keyword can be used in various parts of the code, the
most important construct it builds is dynamic class. From what I've
seen the soon to come C# 4.0 also introduces this keyword, but strange as it
might appear I haven't been influenced by this. In fact, I became aware of it
only when this paper was already completed. Therefore, all similarities are a
mere coincidence. This paper was influenced mainly by three things:
This new class type can inherit from static classes and viceversa, it supports
multiple inheritance, virtual functions and templates. So, the reader can be
assured that dynamic classes don't lose any of the C++ language capabilties.
Moreover, they can be used just like static classes.
A basic example of a dynamic class:
dynamic class basic
{
int a;
};
The only metadata information saved for this almost empty class would be the
name (basic) in order to provide runtime type information and
dynamic creation of objects. The member a won't be part of the metadata for
this class, because it's a private member, thus not accessible from external code. The metadata of a method should be saved similarly to Qt, with the slight
difference that typedefs should be resolved. Thus, if I write:
typedef unsigned int DWORD;
dynamic class dc
{
public:
dc();
void method(DWORD s);
};
The signature should be saved as: void method(unsigned int).
I have already mentioned that private members don't get their metadata stored.
This concept has to be explained further with the following class:
dynamic class simple
{
int a;
public:
int b;
simple() { };
protected:
int c;
};
Members which can be changed by external code (even from a derived class), can be accessed dynamically. Thus, b and c
can be accessed through their names. The pseudo code of the compiled C++ to access the b
member dynamically would be:
v = get_member(simple, "b");
if (v == NULL) { /* throw exception */ }
*((int *) v) = 10;
Of course, this is just an example. Even c, being a protected member, can be
accessed indirectly and not by absolute position. If dynamic access to c
wasn't possible, then no class could
inherit from an external dynamic class. The only exception to the general rule
are private virtual functions which also get their metadata
stored. However, this will be discussed much later.
Moreover, the developer is allowed to control explicitly what is going to be
part of the metadata and what isn't. He can achieve this by using the two
keywords exposed and hidden together with or separated from the keywords
public, private and protected.
dynamic class simple
{
exposed: // (private)
int a;
public:
simple() { };
hidden: // (public)
int b;
exposed protected:
int c;
};
Saving the metadata of a private member might not seem very useful, since
there's no way external code can access directly that member anyway. However,
I'll show the meaning of this when used together with the dynamic library in the
paragraph about the signals and slots framework model.
As the reader can see, apart from using the keyword dynamic, a dynamic class
is declared just like a static class and it can be used in the
same way. A static class can be transformed in a dynamic one, just by putting
the keyword dynamic before class.
If the code of a dynamic class is declared locally its members are accessed directly and not dinamically. This is logical because if I have a code like this:
dynamic class simple
{
public:
simple() { };
void method() { /* do something */ };
};
void f()
{
simple s;
s.method();
}
In this case, method gets called directly by the function f. There
is no need to call it dynamically. In fact, doing so would only produce slower
code. It doesn't matter whether the dynamic class is declared in the same C++
file or not. What matters is the presence of the dynamic class code inside the
C++ project that contains the f function as well: including "simple.h" (when
"simple.cpp" is in the same project) has the same effect.
However, sometimes developers want to call a method dinamically, even if the code of the class is inside the project. This is the case, for instance, when one wants to access a particular method ignoring its type. Qt signals and slots mechanism relies on this key feature and it would be necessary even for an event driven framework like .NET.
To force a dynamic call only a cast is required:
void f()
{
simple s;
((dynamic *) &s)->method();
}This kind of syntax can be used as argument as well:
void dyncall(dynamic & obj)
{
obj.method();
}
void f()
{
simple s;
dyncall(s);
}But what if I want the dynamic object to be a class and not some other kind of object (like a struct)? This can be achieved by specifing the desired kind of object:
void dyncall(dynamic class & obj)
{
obj.method();
}Here's the resulting pseudo-code of how the method gets called:
method = get_method(obj, "void method()");
if (method == NULL) { /* throw exception */ }
method(obj);
The signature of the method to call is retrieved through the parameters (none, in this case). The compiler always knows the parameters type, so it's his job to build the signature to dynamically call a method like the one above. If a the method signature expects an int and the developer passes a char, a cast should be used to build the correct signature, otherwise, in the case of undeclared external objects (discussed later) or generic dynamic calls like this one, the call will fail, since the compiler can't guess the developer's intentions:
// wrong
void dyncall(dynamic class & obj)
{
char c = 10;
obj.method(c);
}
// right
void dyncall(dynamic class & obj)
{
char c = 10;
obj.method((int) c);
}
You may have noticed that in the code samples above no return type was
specified. When the return type is omitted, it is assumed that the function
doesn't return a value, thus the signature of the method is built accordingly,
with a void return type. If the method hadn't a void return type, the
signature would be wrong and the call would consequently fail. To indicate a
different return type other than void, this syntax should be used:
void dyncall(dynamic class & obj)
{
obj.<int>method();
}
A similar syntax is necessary to access members:
void dyncall(dynamic class & obj)
{
obj.<int>var = 100;
}
It's also possible to allocate dynamically a class:
dynamic class simple
{
public:
simple() { };
int method() { /* do something */ };
};
void f()
{
dynamic class *c = new "class simple";
c-><int>method();
delete c;
}
The syntax of the new operator in this code example may seem inconsistent,
but it isn't. I'll explain how it works in the dynamic library paragraph; we have seen how
to force the compiler to dynamically call a method or access a member, and how
to allocate a class dynamically, but most of the dynamism can be achieved only by using the dynamic
library.
My perception of the typeid operator has always been as something which isn't
really part the C++ language. This operator was basically added to retrieve type
names and make dynamic cast operations possible. The names are retrieved thanks
to the RTTI (RunTime Type Information). How the RTTI behaves internally is not
universally defined, even the type names syntax changes depending on the
current compiler. However, the typeid operator becomes essential in the context
of Dynamic C++.
The typeid operator returns the type_info class. The internal
data of this class is compiler specific. The Visual C++ definition, taken from
the SDK, looks like this:
class type_info {
public:
virtual ~type_info();
_CRTIMP_PURE bool __CLR_OR_THIS_CALL operator==(const type_info& rhs) const;
_CRTIMP_PURE bool __CLR_OR_THIS_CALL operator!=(const type_info& rhs) const;
_CRTIMP_PURE int __CLR_OR_THIS_CALL before(const type_info& rhs) const;
_CRTIMP_PURE const char* __CLR_OR_THIS_CALL name(__type_info_node* __ptype_info_node =
&__type_info_root_node) const;
_CRTIMP_PURE const char* __CLR_OR_THIS_CALL raw_name() const;
private:
void *_m_data;
char _m_d_name[1];
__CLR_OR_THIS_CALL type_info(const type_info& rhs);
type_info& __CLR_OR_THIS_CALL operator=(const type_info& rhs);
_CRTIMP_PURE static const char *__CLRCALL_OR_CDECL _Name_base(const type_info *,
__type_info_node* __ptype_info_node);
_CRTIMP_PURE static void __CLRCALL_OR_CDECL _Type_info_dtor(type_info *);
};
The name method is what you generally see used in relation to the typeid
operator:
typeid(var).name()
Also, the comparision operators are overloaded and this allows to make type
comparisions. However, for our purposes, the type_info class should at least,
apart from the name of the type, return its size and primitive type (which can
be defined as a number).
#include <iostream>
#include <typeinfo.h>
using namespace std;
class myclass
{
public:
myclass();
};
int _tmain(int argc, _TCHAR* argv[])
{
cout << "Name: " << typeid(myclass).name() << endl;
cout << "Size: " << typeid(myclass).size() << endl;
cout << "Primitive Type: " << typeid(myclass).ptype();
return 0;
}
The primitive type tells us if the type is a class, a struct or else.
In the next paragraph it will be clear why this information is necessary. I
mentioned earlier that every dynamic class gets its name stored as metadata.
Thus, to retrieve the name of a dynamic class, the typeid operator can always be used.
This isn't always true for static classes. Many times the typeid operator gets solved, like
in the code sample above, statically at compile time. Only in case of
polymorphism the type_info class is filled dinamically through RTTI:
#include <iostream>
#include <typeinfo.h>
using namespace std;
class base
{
public:
base() {};
~base() {};
virtual void vfunction() {};
};
class derived : public base
{
public:
derived() {};
};
int _tmain(int argc, _TCHAR* argv[])
{
base *cb = (base *) new derived;
// prints "derived"
cout << "Name: " << typeid(*cb).name();
return 0;
}
In order for RTTI to be enabled, the base class must at least have one
virtual method apart from its destructor. If the base class hadn't its only
virtual method (vfunction), the code would print the name of the base class.
That's because there isn't polymorphism in C++ without virtual functions. And this is all fine, because in C++ there isn't a case where the type is
unknown. However, in Dynamic C++ there are generic dynamic types. For instance:
void function(dynamic class & c) { }
This function accepts as argument any kind of dynamic class. Thus, to
obtain the class name, the typeid operator has to be used:
void function(dynamic class & c)
{
cout << "Name:" << typeid(c).name();
}
In Dynamic C++, the typeid operator is also used to identify methods:
typeid(class_name::method)
When applied on a method, typeid fills the type_info class with its
signature and some other platform specific information. To avoid ambiguities in
case the method is overloaded an explicit declaration is possible:
typeid(class_name::method(int))
When the typed operator is used without any argument, it returns the
type_info of the current method. In the next paragraph about the dynamic library we will see the
typeid operator in use.
In order to achieve most of the Dynamic C++ runtime capabilities, the dynamic library has to be included. The reason for that is to avoid built-in functions in the C++ language. The philosophy of C++ stands in libraries, which can be summarized as: what you want is what you get. It would be inconsistent to introduce built-in functions (or objects) to handle C++ dynamism.
There are various possibilities to implement the dynamic library. What I'm going to show here is just an idea how it might look like. It's not really important what it looks like in this proposal. The library is the least complicated matter in this paper and its implementation has much more to do with style decisions than technicalities.
Also, I won't show all the functionalities of the library in this paragraph. This paragraph only introduces the library and some of its features. More features will be presented throughout the article when required.
Note: In the examples of the past paragraph, the typeinfo header, which contains
the declaration of the type_info class, has been included. This is not necessary
when including the dynamic library header.
The first code sample is a basic invoke of a dynamic class method:
#include <dynamic>
dynamic class simple
{
public:
simple() { };
void method(int a, int b, char *string) { /* do something */ };
} obj;
void f()
{
int a = 10, b = 20;
dyn::arguments args;
args.add(&a, typeid(int)); // a
args.add(&b, typeid(int)); // b
args.add("hello", typeid(char *)); // string
dyn::invoke_method(&obj, NULL, typeid(void), "method", &args);
}
This invoke example doesn't achieve much more than the direct call to a
method, apart from dynamically choosing the name of the method. I'll discuss how to
dinamically handle types (this example uses the typeid operator which is solved
at compile time) in a moment, but first I have to say something about this piece of code. A
direct call to a dynamic class method is solved by the compiler, whereas the
invoke_method instruction builds the signature of the method and pushes the
arguments on the stack at runtime. To give you an idea of how invoke_method
works, what follows is some pseudo-code. Keep in mind that the real function would
most definitely be written in assembly.
bool invoke_method(dynamic *dynobj,
void *retvar,
const type_info & rettype,
const char *methodname,
const arguments *args,
// [... other arguments ...]
)
{
// build signature out of the method return type,
// name and arguments type
char *signature = build_signature(...);
method *m = get_method(dynobj, signature);
// couldn't find the method in the object?
if (m == NULL)
{
// fill error report
return false;
}
// LIFO stack
for (int i = args.size() - 1; i >= 0; i--)
{
switch (args[i].ptype())
{
case primitive_type_int:
{
// pushes an int on the stack
break;
}
case primitive_type_class:
{
// pushes a class pointer on the stack
break;
}
// [... other cases ...]
}
}
// check if the return type is a class or struct
if (rettype.ptype() == primitive_type_class ||
rettype.ptype() == primitive_type_struct)
{
// if so push the return address as argument
}
// call the method
method->call();
// if the return type is a simple type like an integer,
// copy it to retvar. Otherwise, if it's a class, struct or void,
// don't do anything
if (rettype.ptype() == primitive_type_int ||
rettype.ptype() == primitive_type_bool ||
/* ... */)
{
// copy
}
// adjust the stack
adjust_stack();
return true;
}
To dynamically invoke a method is a bit slow compared to directly calling it, but the reader has to keep in mind that invokes are used only for particular tasks. Nevertheless, I will discuss how to make even invokes faster in a moment.
Handling types dynamically is easy. The type_info class should have a string
argument in one of its constructors, making this syntax possible:
#include <dynamic>
dynamic class simple
{
public:
simple() { };
void method(int a, int b, char *string) { /* do something */ };
} obj;
void f()
{
int a = 10, b = 20;
dyn::arguments args;
args.add(&a, "int"); // a
args.add(&b, "int"); // b
args.add("hello", "char *"); // string
dyn::invoke_method(&obj, NULL, "void", "method", &args);
}
But what if one of the arguments is a dynamic class? In that case, a generic definition can be used (in case there are no overloads with a different dynamic class), since the specific type name of the dynamic class is unimportant. The paragraph about inheritance will show why this is so.
#include <dynamic>
dynamic class parameter
{
public:
parameter() { };
};
dynamic class simple
{
public:
simple() { };
void method(parameter *p) { /* do something */ };
} obj;
void f()
{
parameter p;
dyn::arguments args;
args.add(&p, "dynamic *");
dyn::invoke_method(&obj, NULL, "void", "method", &args);
}
The dynamic use of types should also explain the behaviour of the new
operator we have seen earlier. In fact, the new operator should accept a type_info argument, making
both these kind of syntaxes possible:
dynamic class *c = new typeid(simple);
dynamic class *c = new "class simple";
All the dynamic invokes we have seen are rather slow if we wanted to invoke repeatedly the same method. The overhead caused by the argument list is necessary for these kind of invokes (we will see a different kind of invoke in a moment). However, building each time the method signature and then looking it up in the metadata of the class can be avoided.
#include <dynamic>
dynamic class simple
{
public:
simple() { };
bool isValid(int n) { /* do something */ };
} obj;
void f()
{
int n = 0;
dyn::arguments args;
args.add(&n, typeid(int));
dyn::method m = dyn::get_method(&obj, typeid(isValid(int)));
// or
// dyn::method m = dyn::get_method(&obj, "bool isValid(int)");
if (m.is_null() == true)
return;
for ( ; n < 1000; n++)
{
bool bValid;
m.invoke(&bValid, args);
if (bValid == true)
{
// do something
}
}
}
Of course, if the number of arguments doesn't match the expected one, the
invoke method returns false.
The advantage of argument lists is that they allow to push
parameters (and thus call different overloads of the same function) in a very
dynamic way. This might not always be necessary. In that case, a less
dynamic invoke named call_method can be used.
#include <dynamic>
dynamic class simple
{
public:
simple() { };
void method(int a, int b, char *string) { /* do something */ };
} obj;
void f()
{
dyn::call_method(&obj, typeid(simple::method), NULL, a, b, "hello");
// or
// dyn::call_method(&obj, "void method(int, int, char *)", NULL, a, b, "hello");
}
The NULL argument is a pointer for the type, in this case it isn't used,
since the method is declared void. call_method is a variable argument
list function
declared this way:
bool call_method(dynamic *dynobj, const type_info & mi, void *retvar, ...);
The cases in which the call_method function can be used is when only the method's name
and not its parameters has to be decided at runtime. I'm aware that this
function is not very useful, but I put it here for completeness, since it's
surely faster than invoke_method.
An external dynamic object, meaning an object contained in an external module, can be imported very easily. In fact, for rapid usage, it can be imported with a "class forward" kind of syntax:
extern dynamic class simple;
void f()
{
simple s;
if (s.<bool>isEven((int) 10) == true)
// do something
}
The return type had to be specified and the argument had to be casted (which isn't necessary when a variable is used) just like for a generic dynamic object call (introduced earlier) in order to build the correct signature for the method to call. This can be annoying if done for every method of the external object being called. Thus, to avoid this syntax, an explicit class declaration is necessary.
extern dynamic class simple
{
bool isEven(int);
};
void f()
{
simple s;
if (s.isEven(10) == true)
// do something
}
Only methods which get called need to be declared. The same rule applies to members. Generally, an explicit declaration is advisable, although undeclared external objects can be useful when testing code on the fly.
Note: I used the extern keyword to tell the compiler that the dynamic object
is external, but this is compiler specific. For instance, Visual C++ uses the
__declspec(dllimport) syntax. The connection between the code and the external
module is also left to the compiler. In my opinion, libraries are the most
consistent and efficient option to link the two of them.
Important: To avoid the mistyping of a method or member of an external object, the compiler could check the correctness of it through the library used to import the external object. If the member or method signature is not contained in the library, the developer could be informed by a warning or an error. Of course, this can't prevent code failing at runtime in case the external module has been modified, but it avoids typos.
This paragraph was very short, there's nothing else to say about external dynamic objects if not in relation to other topics. In fact, they will be discussed further in the paragraphs about inheritance and fast C++ dynamism. I needed to introduced them, because I wanted to talk about exceptions.
We have seen in the dynamic library introduction that certain functions, like
method invokes, when they fail, return false. There's no exception being thrown.
I have opted for this behaviour, because, when a method is invoked, the
possibility that the invoke may fail is in most cases taken into account.
Generating exceptions for everything is not really consistent with the C++
style. If I was writing about .NET, which throws an exception even if an openfile method fails, then I might consider it (or maybe not, after all), but in
C++ things are different. Not that exceptions are never used, in fact I reserved
exceptions for dynamic code like the following:
void dyncall(dynamic class & obj)
{
obj.<int>method();
}
There's no other way to signal to the code that the call has failed if not by throwing an exception. The main reason for a call like this to fail is that the method signature couldn't be located in the metadata of the object. If there is a chance that such a call could fail, then the developer should put the call in a try block.
#include <iostream>
#include <dynamic>
using namespace std;
void dyncall(dynamic class & obj)
{
try
{
obj.<int>method();
}
catch (const dyn::exception & e)
{
cout << exception.verbose();
}
}
The main rule for exceptions is that they are being thrown if there's no other way to tell the executing code that an operation has failed.
This paragraph begins to discuss Dynamic C++ internals and I will try to be as clear as possible. To understand inheritance, it is necessary to dicuss the physical layouts of static classes. It's not the scope of this article to throughoutly explain C++ internals, but they're very simple and so I'll give it a try anyway. I sort of assumed earlier in the article that the reader already knew this stuff, at least partly, but to explain inheritance in a dynamic context I can't assume that the reader has already all the necessary knowledge.
Let's take a minimal class:
class basic
{
int x, y;
public:
basic() {};
};
The layout of this class, meaning the compiled representation of it, is the following:
class basic size(8):
+---
0 | x
4 | y
+---
Note: I'm generating these kinds of diagrams through the undocumented /d1reportSingleClassLayout switch provided by Visual C++. One can open the Visual C++ Command Prompt and type: cl main.cpp /Zp2 /c /d1reportSingleClassLayout+nameoftheclass. As for the case above, the command looks like this: cl main.cpp /Zp2 /c /d1reportSingleClassLayoutbasic. It's also possible to show the layout of all classes. Just type: cl main.cpp /Zp2 /c /d1reportAllClassLayout. Note: the use of these undocumented switches is reported on the Visual C++ Team Blog and on OpenRCE.
A more advanced example:
class simple
{
int a, b;
public:
simple() {};
~simple() {};
virtual void method() {};
};
class advanced : public simple
{
int c;
public:
advanced() {};
~advanced() {};
};
And it produces these layouts:
class simple size(12):
+---
0 | {vfptr}
4 | a
8 | b
+---
simple::$vftable@:
| &simple_meta
| 0
0 | &simple::method
simple::method this adjustor: 0
class advanced size(16):
+---
| +--- (base class simple)
0 | | {vfptr}
4 | | a
8 | | b
| +---
12 | c
+---
advanced::$vftable@:
| &advanced_meta
| 0
0 | &simple::method
As you can see, when a class inherits from another class the members of the base class come before the members of the derived class. This is true for all members of the derived class except for the vfptr pointer. When a class has one or more virtual methods, the first member it stores in its layout is a pointer to the virtual functions table. This table stores the addresses of the virtual methods of the class. If the derived class had virtual methods and the base class didn't, the vfptr member would be the first member of the derived class, followed by the base class members and then by the other members of the derived class.
You can look at the layout above as structure just like this one:
struct advanced_data
{
// simple class members
void *vfptr;
int a;
int b;
// advanced class members
int c;
};
The pointer to this data gets passed to the methods of the advanced class as
first argument (called the this argument). Visual C++ stores the this
pointer in the ecx register on x86 platforms, instead of using the stack like
GCC (I'm using version 3.4.2) does, which gets the name of "this calling
convention".
In case the class advanced had like
its base class a virtual method, its virtual functions table would look like
this:
class advanced size(16):
+---
| +--- (base class simple)
0 | | {vfptr}
4 | | a
8 | | b
| +---
12 | c
+---
advanced::$vftable@:
| &advanced_meta
| 0
0 | &simple::method
1 | &advanced::method2
If the method of the advanced class was declared void method(), it would
overwrite the &simple::method pointer inside the virtual functions table and
become &advanced::method. And now, an example with multiple inheritance:
class not_polymorpic
{
int s, t;
public:
not_polymorpic() {};
};
class basic : public not_polymorpic
{
int x, y;
public:
basic() {};
~basic() {};
virtual void method3() {};
};
class simple : public basic
{
int a, b;
public:
simple() {};
~simple() {};
virtual void method() {};
};
class simple2
{
int k, j;
public:
simple2() {};
~simple2() {};
virtual void method2() {};
};
class advanced : public simple, public simple2
{
int c;
public:
advanced() {};
~advanced() {};
virtual void method2() {};
};
And its layout:
class advanced size(44):
+---
| +--- (base class simple)
| | +--- (base class basic)
0 | | | {vfptr}
| | | +--- (base class not_polymorpic)
4 | | | | s
8 | | | | t
| | | +---
12 | | | x
16 | | | y
| | +---
20 | | a
24 | | b
| +---
| +--- (base class simple2)
28 | | {vfptr}
32 | | k
36 | | j
| +---
40 | c
+---
advanced::$vftable@simple@:
| &advanced_meta
| 0
0 | &basic::method3
1 | &simple::method
advanced::$vftable@simple2@:
| -28
0 | &advanced::method2
advanced::method2 this adjustor: 28
Only the base classes with virtual functions have a vfptr member, obviously.
When a method of the simple2 class is called, the this pointer
passed to method is incremented by 28, that's because the members of the class simple2
begin at that offset.
I can't claim that I explained everything there is to know about C++ internals (in fact, I haven't mentioned the RTTI internals, which are compiler specific anyway), but it should suffice to understand the content of this article.
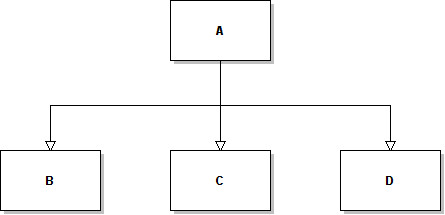
What follows is a layout approach I have discarded. Let's consider this simple hierarchy of (local) dynamic classes:
It would be possible to produce a contiguous layout out of this hierarchy. And it might look like this:
dynamic class A - metadata_ptr - data_offset dynamic class B - metadata_ptr - data_offset dynamic class C - metadata_ptr - data_offset dynamic class D - metadata_ptr - data_offset - CONTIGUOUS DATA BLOCK
But what happens when the class C is an external object? In that case, in
order to build a contiguous data block of the members of
all classes, it should
be necessary to enquire first the size of C. Only afterwards the code could
allocate the data block, which then requires to iterate through all the classes
to set up their data correctly. In fact, it can't be assumed that C is a
pure base
class. It may be a derived class. Only the module which contains the C
class knows how to fill its own
part of the data block. We could look up the metadata of the class and then fill
the data block, but it adds up to the same effort. Imagine if the class hierarchy was much more complicated
than the simple one above.
I think this layout type is rather slow and unefficient for many reasons. A much more logical way to organize the layout is by using pointers. If we assume that every dynamic class is represented by a pointer, then setting up a layout is much easier. Yes, it results in a non-contiguous data block. However, with an intelligent memory allocation, the occupied memory should be the same. Let's take this class hierarchy:
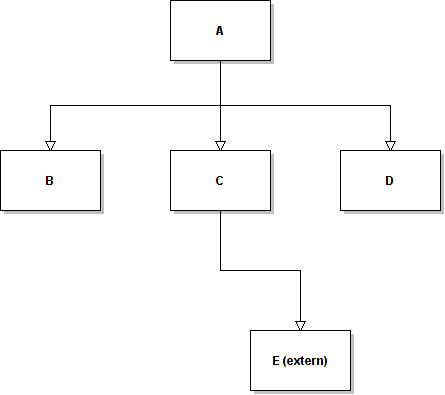
As you can see, the E class is an external object. The resulting layout would be:
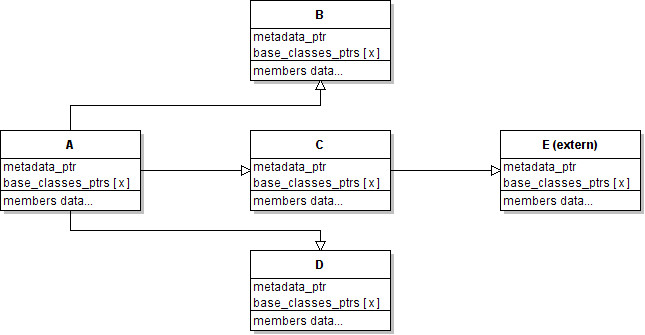
It doesn't matter to the layout creation function whether the class E has a
base class or not, every class provides for its own allocation. The number of
base class pointers (if any) which follow the metadata is retrieved from the
metadata of the class. Classes of the same type share the same metadata. Thus,
metadata_ptr refers static data.
This kind of layout doesn't affect performances of local dynamic classes.
Let's say that the local code wants to call a method of the D class. The compiler knows that the D class is the third child of the A class
and also knows that the D class has no base class. Which means that the
compiler produces this code (what follows is pseudo-code, as usual):
D_ptr = *((ptr *) A_ptr + (sizeof (ptr *) * 3)); // retrieve D class pointer D_method((this *) (D_ptr + sizeof (ptr *)), ....); // call the method
Actually, since D is a local class, it gets called even faster as showed
later in the fast C++ dynamism paragraph. The this pointer of the D class points directly to the data after the
metadata pointer, since the class has no base class pointers. Beware that this
is not the final layout of dynamic classes, I'm just proceeding one step at a
time.
The allocation of dynamic classes is quite easy to explain. The metadata of every class should reference the metadata of its base classes, so that the allocation of a class becomes a simple tree iteration matter.
The calling of the constructors works just like for static classes: before
executing the code written by the developer in the constructor, the constructors
of the base classes get called. Those constructors call the constructors of
their base classes and so on. So, after having prepared the class layout, it is only
necessary to call the constructor of the class on top of the hierarchy, in our
case A, which then calls all other constructors. The constructors of external
dynamic classes, like E, are called dynamically:
void B(*this) { /* Developer's Code */ }
void C(*this) { /* Developer's Code */ }
void C(*this)
{
E_constructor = get_method(E_class_ptr, "E()");
if (E_constructor == NULL) { /* throw exception */ }
E_constructor(E_this);
/* Developer's Code */
}
void A(*this)
{
B(B_this);
C(C_this);
D(D_this);
/* Developer's Code */
}
The same applies to destructors.
When calling the method of a local dynamic class, the compiler calls it statically. But what happens when a method gets called dynamically?
void dyncall(dynamic class & obj)
{
obj.print();
}
The internal get_method function will iterate through the class hierarchy
tree until it finds a corresponding signature. If both the base classes B and
D had the same print method, then only the print method of the B class
would be called, since B comes before D in the tree. This rule doesn't apply
in static classes, where a code like the following one can't be compiled:
class B
{
public:
B() {};
void print() { printf("\nHello"); };
};
class C
{
public:
C() {};
void print() { printf("\nWorld"); };
};
class A : public B, C
{
public:
A() {};
};
void f()
{
A a;
a.print();
}
The reason for the code not being compilable is that the compiler can't
establish the priority. Both print methods stand on the same level. This sample
would compile if the A class also had a print method. In that case the
priority is clear to the compiler, since A stands on a higher level than B
and C. In Dynamic C++ the compiler can do priority checks on local classes and
also
on external ones through libraries. However, if the module containing the, let's
assume, external B class was changed, implementing a print method and
the developer's
original intention was to call the print method of the C class, then the wrong
method would be called, breaking the code. To avoid this, the only way is to
perform a signature check on all classes which stand on a same level in the
tree. If two or more classes have the same signature of the method being called,
an exception should be thrown. Since this procedure is a little bit time
consuming, maybe it should be reserved to debug versions of the compiled
program. Multiple inheritance is often the cause of problems, even when used for
static classes, so it shouldn't be a surprise that even in the context of dynamic
classes it presents some challenges. That's why multiple inheritance should be
used with care as usual.
I mentioned earlier in the paper that dynamic classes can inherit static classes and viceversa.
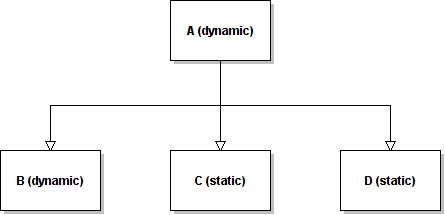
Static classes are merged together as always. The resulting layout of this hierarchy is:

Static classes are incorporated in the highest dynamic class in the hierarchy tree. The other dynamic classes follow the tree layout showed earlier. If the highest class isn't a dynamic one, then the behaviour changes slightly. Let's consider the hierarchy above inverted:
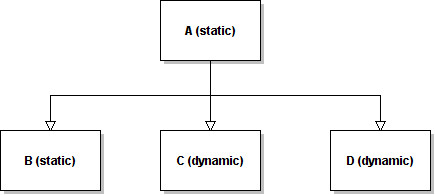
In this case, the static classes are merged together and put on top as usual, but wrapped in a dynamic layout. The dynamic layout has a restricted metadata and its purpose is only to link the inherited dynamic classes.
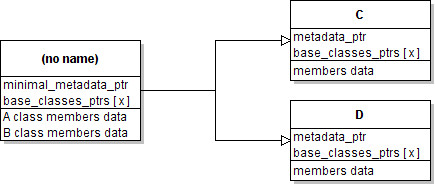
As one can see, the internals of static classes derived from or inherited by
dynamic ones, are essentially the same as in normal C++. The tree layout
approach makes it possible to have a fixed size layout for classes. This is
important when considering statically allocated objects (meaning not dynamically
allocated with the new operator). The local code can't guess the size of the external dynamic class, but
it can already set up the layout for local dynamic classes, so that only the gap
between local and external objects has to be solved.
Copying a dynamic class is not as straightforward as for a static class. In a
static context a simple memcpy is enough, because class layouts are contiguous
memory blocks. However, to copy dynamic classes, it's necessary to iterate
through their class tree and copy each base class separately.
The sizeof operator behaves accordingly to class copying, meaning it
returns only the size of the current class, not the size of its inherited
classes.
extern dynamic class C;
dynamic class B : public C
{
// content
};
dynamic class A : public B
{
// content
};
/*
sizeof(A) <--- returns the size of "A", and "A" only, statically
sizeof(B) <--- returns the size of "B", and "B" only, statically
sizeof(C) <--- returns the size of "C", and "C" only, dynamically
*/
The size of a dynamic class can be calculated from the information contained in its metadata.
Because of the tree layout approach showed in this paragraph, it should be clear why dynamic classes don't suffer of FBC problems.
Virtual functions, in the context of Dynamic C++, have the same role as usual. To overwrite the virtual function of an external object, it is necessary to declare it.
extern dynamic class simple
{
public:
virtual void b();
};
class advanced
{
public:
void a();
void b();
void c();
void d();
};
In this code example, only the b method gets overwritten, even if class
simple had among its virtual methods a, c or d. It would be possible to
resolve all methods with the libraries, but this is a bad paradigm, because it
hides from the code what happens. A developer should have a clear sight of what
happens at runtime just by looking at the code.
Also, as you can notice, the b method is being overwritten by one of a
static class. That doesn't change anything. The static class accesses the
members of the external object dynamically, while accessing local members statically
(a dynamic class would do exactly the same).
The internals of virtual functions are perhaps a bit more difficult to explain, but I'll give it a try.
dynamic class B
{
virtual void m1(int i);
void m2(int i) { m1(i); };
};
dynamic class A : public B
{
void m1(int i);
};
void f()
{
A a;
B *b = (B *) &a;
b->m1(10);
a->m2(10);
}
The problem with virtual functions is that the this pointer of the owning
class has to be passed to the method. Let's consider the cast to B and the
call to the method m1. The this pointer passed to m1, if this wasn't a
virtual function, would be a pointer to the B tree element. But the method
m1 has been overwritten by the A class. Thus, the method needs a pointer to
the A tree element as this argument. The same applies when the method m2
is called, since m2 gets a pointer to the B tree element and, in order to
call the overwritten m1 method, needs a pointer to A.
The difficulty in thinking about a valid system for virtual functions was to take into account performances and memory consumption. However, I think I came up with a very efficient solution.
Every class in the tree should contain a table of pointers. One pointer for every virtual function in that particular class.
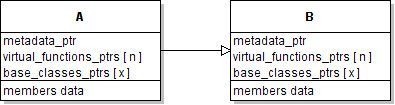
The number of virtual functions in a class can be obtained from the metadata,
of course. When a virtual method is looked up in the metadata, what can be
retrieved isn't the address of the method, but an index into the table. Each
member of this table points to the entry of a vtable (so they're actually vtable
pointers). When the virtual function of class is not being overwritten by
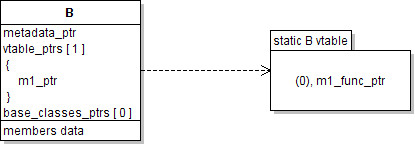
another one, its entry in the table points to a static vtable, shared by all
classes of the same type. Let's say B was allocated on its own:
Instead, if we consider A derived from B:
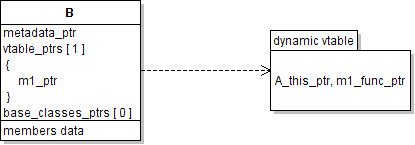
This time the entry points to a dynamic vtable. What this means is that a dynamic vtable is created only for overwritten methods. All the other virtual methods, which aren't overwritten, point to a static vtable which, like the metadata, is being shared for all classes of the same type. This reduces memory usage to a minimum.
Of course, the static and the dynamic vtables are different. A dynamic
vtable needs to specify a this pointer for every method, whereas a static
vtable doesn't (otherwise it wouldn't be static in the first place). Let's
say the m2 method is being called like in the code example above. This is the
pseudo-assembly code generated to call m1. Beware, this isn't real assembly, I
just want to show the necessary stack operations.
m2(int i):
{
; parameters
push i
; end
push B_this_ptr
push m1_vtable_ptr
call vfunc_standard_stub
ret ; end of m2 method
}
; this stub gets executed for all virtual methods
vfunc_standard_stub()
{
; take from the stack the vtable pointer for the m1 method
pop reg1
; look up the vtable
; first pointer size data into reg2
mov reg2, [reg1]
; reg2 == 0 ?
cmp reg2, 0
je static_vtable_next
; check where reg1 points
cmp reg1, static_range_min
; reg1 < min
jl dynamic_vtable
cmp reg1, static_range_max
; reg1 > max
ja dynamic_vtable
static_vtable_next:
; it's a static vtable, but first pointer was null
; which means a null "this" pointers
; the address of the method follows, put it in reg2
mov reg2, [reg1 + sizeof (reg)]
static_vtable:
; the "this" pointer given to the stub is the right one
; since the method hasn't been overwritten
; call the method straightaway
call reg2
ret
dynamic_vtable:
; it's a dynamic vtable and so the "this" pointer
; needs to be fixed
; pop from the stack the old one
pop
; push the right one
push reg2
; get the address of the method to call
mov reg2, [reg1 + sizeof (reg)]
call reg2
ret
}
As you can see, I used two methods to check if the vtable is a static one.
The second method checks if the this pointer is null. In that case, it has to
be a static vtable. However, putting a null pointer before every virtual method
pointer in a static vtable is a waste of memory. It would be better if
each module defined a range where only static data is stored. Inside that
address range no dynamic vtable can exists. Thus, if reg1 points there, it must
be a static vtable.
But where do dynamic tables live? It doesn't really matter, but they should be considered as owend by the top element of the local tree hierarchy.
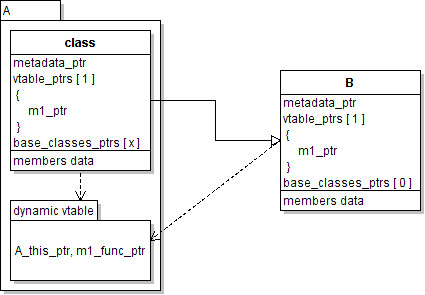
I said local tree hierarchy, because external objects have their own dynamic vtables. This is necessary as we don't know which methods are being overwritten between an external object and its inherited classes.
extern dynamic class B
{
virtual void m1();
};
dynamic class A : public B
{
// content
void m1();
};
In this case, B is an external class. B might inherit a C class
contained in the same external module and overwrite one or more of its methods.
The declaration of B in our code sample doesn't tell us all these things, so
it can't be our code to handle them. Forcing the developer to declare these
things explicitly makes our whole code not-so-dynamic and also brings us back to
the FBC problem. If we relied only on the dynamic vtable contained in
A, all the methods C gets overwritten by B would be missing. This doesn't
mean that an external vtable pointers array can't point to our local dynamic
vtable. In fact, it's quite the opposite. This is the layout of the classes:
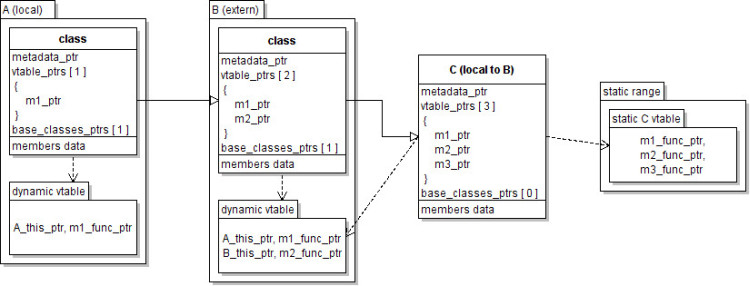
The method m3 contained in the C class is not being overwritten by any of
the derived classes and so it is referenced by the static vtable of the C
class. The m2_ptr of C references the second entry of the dynamic vtable of
the B class, which is the top element of the external tree hierarchy. The
first entry of the external dynamic vtable was changed in order to reference the
m1 method of the class A.
This system is extremely efficient and fast, since every local tree hierarchy is solved statically at compile time and only the bindings between one module and another have to be solved at runtime. I call this concept "virtual gap". The bindings are solved only once for every type, as we'll see in the paragraph about fast C++ dynamism.
But what happens if the B class hasn't any m1 method and only the C
class has? Doesn't matter. Virtual methods are solved between modules by
checking each element of the external tree for the virtual method. It might also
be possible that none of the external classes has the virtual method of the
local derived class. In that case, just like for the C class above, the static
table of the local class will be referenced. No kind of FBC problem
related to virtual functions can occur with this mechanism.
As mentioned, static classes can overwrite virtual functions of dynamic
classes (and viceversa). The only thing that changes is the this pointer
inside the dynamic vtable, which for static classes will be adjusted by their
relative offset.
The last thing which ought to be discussed is memory usage. Virtual functions in dynamic classes are surely a bit memory expensive, because of all the tables. However, if we consider a base class and its derived class with 100 (and this is a very large number) overwritten virtual functions, we'll see that the memory overhead (on 32-bit platforms) for each instance of this class would be 1600 bytes, not much more than 1 kb. If these 100 functions weren't overwritten, then the overhead would just be 800 bytes. This overhead is nothing compared to the overhead of other technologies which offer the same capabilities.
Pure virtual functions of dynamic classes behave locally the same way the ones of static classes do. Meaning that it isn't possible to compile:
extern dynamic class C;
dynamic class B
{
public:
B();
virtual void method() = 0;
};
dynamic class A : public B
{
A();
};
void f()
{
A *a = new A();
}
However, if the B class was contained in an external module and its library
wasn't up-to-date, then it might happen that a pure virtual function contained
in B isn't overwritten at runtime. Calling a pure virtual function
results in an exception being thrown.
The implementation of pure virtuals is the same as for every other virtual function. The only difference is that their static vtable pointers refer error code, so that calling the code of one of these functions produces an exception.
Let's consider:
extern dynamic class A;
This class may have virtual functions we don't know of, but we might still be able to allocate the type. The best response to this are runtime exceptions when a pure virtual function is called. Trying to address completely the problem at compile time, would drastically reduce dynamism. Libraries can be used only for pure virtual functions they are aware of. But, as already mentioned, discrepancies between a library and the actual module are possible.
At first I thought there were some restrictions to the use of templates. Mainly, because templates are solved at compile time and when talking about C++ templates you wouldn't think about using them externally. However, I came up with an idea of combining dynamic classes and templates which, in my opinion, makes the whole Dynamic C++ proposal most interesting.
Dynamic templates can be declared in two ways:
template <dynamic T>
T Max(T a, T b)
{
return (a > b ? a : b);
}
// or
dynamic template <T>
T Max(T a, T b)
{
return (a > b ? a : b);
}
In the second declaration all types are considered dynamic, so it isn't necessary to specify it. Meanwhile, in the first declaration, the template really is a dynamic template only when all of the types inside the brackets are dynamic types.
template <dynamic T, class R>
This causes the template not being dynamic.
Static templates are a bit faster, although not very much, while dynamic ones are, most of the time, less memory consuming. Let's consider an application of the template above:
dynamic template <T>
T Max(T a, T b)
{
return (a > b ? a : b);
}
dynamic class Number
{
// content
};
dynamic class String
{
// content
};
void f()
{
Number x(10), y(20);
String a("hello"), b("hell");
Number z = Max(x, y);
String c = Max(a, b);
}
The code of Max is generated only once. That is because when called, it
looks up the overload of the > operator for the given type. The resulting
pseudo-code for the comparision of String classes would be:
Max(type, a, b)
{
char *signature = generate_signature(type);
// signature = "bool operator>(String & other)"
greater_than = get_method(a, signature);
if (greater_than == NULL) { /* throw exception */ }
if (greater_than(b) == true)
return a;
return b;
}
This might seem bloated and not very fast, but it isn't. It is bloated for a
very small template function like Max, but it is very small when considering
large template classes or functions. In that case, it is much more memory
consuming to generate different code for each different template usage. And it isn't slow
either. In fact, it is very fast: the pseudo-code above is not complete and I'll
show why dynamic templates are fast in the paragraph about fast C++ dynamism.
Nevertheless, being fast or memory friendly isn't the main advantage of dynamic templates. The main advantage is that it is possible to import them from external modules. The example above could be rewritten this way:
// contained in module "A"
extern dynamic template <T> T Max(T, T);
// contained in module "B"
extern dynamic class Number;
extern dynamic class String;
void f()
{
Number x((int) 10), y((int) 20);
String a("hello"), b("hell");
Number z = Max(x, y);
String c = Max(a, b);
}
This is the generic compiled code I mentioned earlier when enumerating the
advantages of Dynamic C++. It is possible to write generic code, compile it and
use it dynamically. It is also the reason why dynamic code can be compiled
faster. Static templates have to be compiled every time one is compiling the
code which uses them. Viceversa, dynamic templates can be precompiled. The use
of the extern keyword shouldn't be confused with static external templates
brought by the new C++0x standard.
This may not seem such big an advantage with a simple function like Max, but
let's consider a better usage example. We could, for instance, easily separate
an external RSA implementation from its big number class.
// contained in module "A"
extern dynamic template <T> class RSACrypter;
// contained in module "B"
extern dynamic class BigNum;
void f(void *data, int len)
{
RSACrypter<BigNum> rsa;
rsa.GenerateKey((int) 4096);
rsa.EncryptData(data, len);
}
The BigNum class is an external object, but it could be a local as well.
The important thing to notice in this example is that both the BigNum class and the
RSACrypter class are already compiled and bound at runtime.
I'll explain in the fast C++ dynamism paragraph why using a template like the
above one isn't the same thing as passing to RSACrypter a generic dynamic
class to use as big number implementation.
This paragraph can be considered a sub-proposal. The problem with primitive types is that they're not dynamic. So, this code wouldn't be possible with dynamic templates:
extern dynamic template <T> T Max(T, T);
void f()
{
int x = 10, y = 20;
int z = Max(x, y);
}
However, this can be solved by wrapping primitive types (like integers, floats, doubles etc.) inside dynamic classes without the developer noticing it. The dynamic wrapper would provide support for all common operations on numbers. A wrapper is generated only once for each different type, making the memory cost of the implementation very inexpensive.
This is the paragraph where all what I've said until now comes together, in the sense that, if Dynamic C++ hadn't excellent performances, then the whole idea would be ludicrous anyway.
In Dynamic C++ every overhead exists only once for a certain operation. Calling a method of an external dynamic object, using an external dynamic template, filling the virtual gap between objects of two separate modules: it all causes an overhead only the first time.
I divided this paragraph in small sub-paragraphs for better comprehension of the different optimizations.
As already mentioned, local classes have no overhead at all. The only thing
to explain here is how the optimized adjustement of the this pointer works for
local classes. Let's consider this simple hierarchy of local dynamic classes:
Since they are all local classes, their tree items can be allocated
contiguously. So, locally accessing the members of C means adjusting the
this pointer of A by the size of the A and B class. So, for local
dynamic classes there's no overhead at all. Meanwhile, to adjust the this
pointer of an external object, it is necessary to iterate through the tree.
External dynamic classes are, obviously, handled dynamically. This means that every member or method is solved at runtime, but only once. And it is lazy binding most of the times, meaning that a method of an external object is solved only when it is used the first time. Let's consider this code sample:
extern dynamic class simple;
void f()
{
simple s;
s.<bool>var = false;
if (s.<bool>isEven((int) 10) == true)
// do something
}
When executed, the main application will go through the metadata table of the
external class simple (and of its inherited classes if necessary). The first
small optimization which should be considered is how to search for a method. A
string comparision of every method signature is quite inefficient. A hash
comparision or storing the signatures of the methods in an alphabetically
ordered tree would significantly speed up search operations.
The compiler creates a binding structure for every external dynamic class. The binding structure for the class above would be:
struct simple_binder
{
// members
ushort class_index;
uint var_offset;
// methods
ushort class_index;
void *isEven_ptr;
};
var_offset is the this pointer relative position of the var member.
isEven_ptr points to the method isEven. class_index represents the tree
item index of the class which owns the member or method. However, adjusting the
this pointer through an index every time a method is called is not really
fast. This can be avoided by providing every class with a pointer to a table
solved at runtime of this pointers ordered by index.
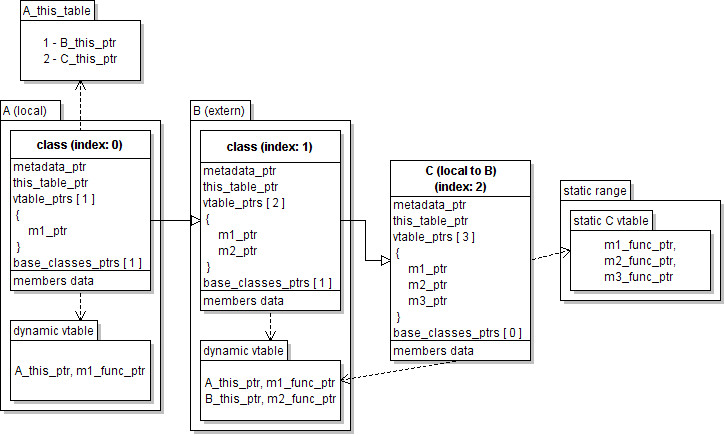
B doesn't need a this pointers table, because all its inherited classes
(C) are local. To better illustrate the concept, let's say the isEven method
is called for the first time. It is checked whether the isEven_ptr of the
binding structure is null. If so, then it is clear that the method has never been
called. The metadata of the external class (and its inherited classes) is looked
up searching for the method. When the method is found, isEven_ptr is set along
with the class_index field. These two fields are set only once during
execution. What happens next is that the this pointers table for the external
class is created and the pointer of the class to that table is set. The table is
filled at the class index position with the this pointer of the class which
exports the isEven method. The first item of the table represents the size in
items of the table.
The second time the isEven method of the same simple class instance is
called, the class_index field is used to get the right this pointer for the
isEven method. If the method is owned by the top class in the hierarchy, then
the class_field is zero and the top this pointer has to be used.
When isEven is first called for a new instance of the class, then the
class_index field is used to immediately iterate to the right tree position
and retrieve so the this pointer, which is then being set to the this
pointers table of the new class. This system is convenient, since for every
inherited class of simple the this pointer is solved
only once for every method or member and class_index fields are shared among classes of the
same type.
// we assume that "isEven" is owend by a subclass of "simple"
// and it's not a virtual function
extern dynamic class simple;
void f()
{
// first instance of "simple"
simple s1;
// first call:
// the method pointer and the class index are solved;
// the "this" pointers table for "s" is created and
// the current "this" pointer is set to the class index
// location inside the table.
// The method is then called.
//
// maximum overhead: the method pointer and the class index
// have to be retrieved, then the pointers table has to be set
s1.<bool>isEven((int) 10);
// second call:
// the "class_index" field is used to retrieve the right
// "this" pointer for the method from the pointers table.
// The method is called.
//
// minimum overhead: nothing has to be solved
s1.<bool>isEven((int) 20);
// second instance of "simple"
simple s2;
// third call on a different instance of the same class:
// the already solved "class_index" field of the binding
// struct is used to get the right "this" pointer for the
// method; the pointers table for "s2" is set accordingly.
// The method is called.
//
// partial overhead: the "this" pointer has to be solved
// given the "class_index" and the table has to be set
s2.<bool>isEven((int) 30);
}
Virtual functions are treated a bit differently. The class_index field
(which is 16-bit value) encodes the class index in its first 15 bits. I think
2^15 (32768) inheritances are quite sufficient. The highest bit, when set, signals
that the method is virtual. When the method is virtual, the method pointer is a
relative offset to the vtable pointer inside the class. When calling a virtual
method, it is necessary to sum the this pointer to the relative offset to
obtain a pointer to the vtable location of the method.
Let's consider the memory consumption of a large dynamic class named
advanced with 100
methods, 20 of them are overwritten virtual methods. The class has two base classes.
Of course, memory usage has much to do with how the virtual functions are
disposed, but in an average context the following calculation would be valid (on
32-bit platforms):
Overhead per instance: 240 bytes (dynamic vtable + vtable pointers) + 12 bytes
(this pointers table)
Static overhead: metadata size + static vtable + binding struct
What matters is the overhead on a per instance base and it isn't very much:
252 bytes. This means that, every time a new instance of the class advanced is
created, in addition to the data of the members 252 bytes are allocated.
To further optimize, the this pointer field in the vtables could be
replaced by an index (2 bytes), which represents an entry into the this
pointers table. This would be convenient on platforms where pointers are larger
than 32 bits. However, to introduce this optimization, it is necessary that
subclasses had a pointer to the this pointers table of the top class in the
tree hierarchy.
The virtual gap represents the virtual function bindings (solved dynamically) between two classes which have a derived - base relationship and are contained in two different modules. As explained in the paragraph about virtual functions, those declared in local dynamic classes are solved statically by the compiler. What needs to be solved at runtime is the gap of virtual functions bindings between local and external objects.
The virtual gap can be solved quite easily by using the binding structure already seen in the past paragraph. The only thing which should be noted is that lazy binding doesn't apply to virtual functions. In fact, they are solved when the class is being allocated for the first time. This may cause a little bit of overhead when the first instance of a class is created, but is necessary since otherwise the not yet overwritten methods could be called from a base class.
Dynamic templates are very optimized.
Let's consider this template:
dynamic template <T>
T Max(T a, T b)
{
return (a > b ? a : b);
}
The Max function builds bindings for every operation executed on T. In
the case above, it builds this binding structure:
struct T_binder
{
// methods
ushort class_index;
void *greater_than_ptr; // bool operator>(type & other)
};
So that next time it calls the greater_than method, it's a direct call.
It is a waste of time to create a new binding structure if the type used as
template has already been used. This can be avoided by passing an additional
pointer to Max. This pointer really is a pointer to pointer to the binding
structure created for a certain type by the function or class which owns the
template. In pseudo-code:
void *int_bindings_for_Max = NULL;
int f(int x, int y)
{
return Max(&int_bindings_for_Max, x, y);
}
The pointer is set by Max, since the method or class which uses the
template knows how many bindings
it needs (this is especially true for external templates).
External dynamic template classes have a local binding structure as usual. Let's consider this code sample we've already seen:
// contained in module "A"
extern dynamic template <T> class RSACrypter;
// contained in module "B"
extern dynamic class BigNum;
void f(void *data, int len)
{
RSACrypter<BigNum> rsa;
rsa.GenerateKey((int) 4096);
rsa.EncryptData(data, len);
}
The binding structure for RSACrypter would be:
struct RSACrypter_binder
{
// methods
ushort class_index;
void *GenerateKey_ptr;
ushort class_index;
void *EncryptData_ptr;
// template bindings
void *BigNum_bindings;
};
The combination of usual bindings applied to template classes and internal bindings used by the template class (or function) make dynamic templates extremly fast. There's a bit of overhead in establishing the bindings, but once the bindings are established the execution speed is very fast.
Binding images are the ultimate solution to obtain optimal performances. It is possible to store the binding structures inside external files and save them when the execution of the application is over, so that the methods and members of an external class are solved only once on a given system. Of course, all pointers contained in binding structures would have to be stored as relative virtual addresses and adjusted to the image base of the module when the binding image is loaded.
The storage of binding structures is easy to imagine. The storage of template bindings is a bit different, since the binding image of the application can't know the size of the binding structure for an external template. The binding structures for templates are appened at the end of the binding image and are referred by an offset inside the class used as template. In regard of the example seen above:
struct RSACrypter_binder
{
// methods
ushort class_index;
uint GenerateKey_RVA;
ushort class_index;
uint EncryptData_RVA;
// template bindings
uint BigNum_bindings_offset;
};
Actually, in order to correctly store the bindings for the BigNum class, it
would be necessary that the binding structure provided at least the number of
its items.
Binding images would have to be updated at the end of execution everytime new items of binding structures have been solved. Binding images are invalidated, and thus need to be refilled completely, when the version of the external module they refer changes.
Binding images take inspiration from .NET native images. They work in a totally different way, but play the same role in minimizing execution time on the local system.
In this paragraph I'm going to show the current status of delegates and a possible implementation in the context of dynamic classes.
Method delegates have always been a problem in C++. This is caused mainly by the presence of the multiple inheritance feature of C++ and how it is implemented. Let's consider the layout of a class I already showed when discussing C++ internals:
class advanced size(44):
+---
| +--- (base class simple)
| | +--- (base class basic)
0 | | | {vfptr}
| | | +--- (base class not_polymorpic)
4 | | | | s
8 | | | | t
| | | +---
12 | | | x
16 | | | y
| | +---
20 | | a
24 | | b
| +---
| +--- (base class simple2)
28 | | {vfptr}
32 | | k
36 | | j
| +---
40 | c
+---
It is obvious that, in order to call a method of the simple2 class, it is
necessary to adjust the this pointer of advanced. So, how can a delegate
know how to adjust the this pointer? If the delegate is implemented using
templates, every operation is typed and so it's not a problem, but delegates
can't be implemented using function pointers, not only because of the this
pointer adjustment, but also because they're unsafe. This code alone
corrupts the stack and might even result in an access violation:
void (*corrupt)();
corrupt = (void (*)()) &strlen;
corrupt();
And there's no other way of correctly adjusting the this pointer in a
static context without typed operations, thus templates are necessary. A delegate
implementation based on templates can be found in the Boost library. Here's a
short code sample, taken from the Boost documentation, which shows how to
implement a delegate combining Boost.Bind with Boost.Function:
class button
{
public:
boost::function<void()> onClick;
};
class player
{
public:
void play();
void stop();
};
button playButton, stopButton;
player thePlayer;
void connect()
{
playButton.onClick = boost::bind(&player::play, &thePlayer);
stopButton.onClick = boost::bind(&player::stop, &thePlayer);
}
However, using templates also brings disadvantages:
Point 1 can be discarded from the list if we consider the soon to come C++0x standard which introduces variadic templates. However, before discussing variadic templates, let's consider current implementations like the one seen above.
Let's see the overloading code for Boost.Function:
#ifndef BOOST_FUNCTION_MAX_ARGS
# define BOOST_FUNCTION_MAX_ARGS 10
#endif // BOOST_FUNCTION_MAX_ARGS
// [...]
// Visual Age C++ doesn't handle the file iteration well
#if BOOST_WORKAROUND(__IBMCPP__, >= 500)
# if BOOST_FUNCTION_MAX_ARGS >= 0
# include <boost/function/function0.hpp>
# endif
# if BOOST_FUNCTION_MAX_ARGS >= 1
# include <boost/function/function1.hpp>
# endif
# if BOOST_FUNCTION_MAX_ARGS >= 2
# include <boost/function/function2.hpp>
# endif
# if BOOST_FUNCTION_MAX_ARGS >= 3
# include <boost/function/function3.hpp>
# endif
# if BOOST_FUNCTION_MAX_ARGS >= 4
# include <boost/function/function4.hpp>
# endif
// etc.
A 'functionX.hpp' file contains the following code:
#define BOOST_FUNCTION_NUM_ARGS 2
#include <boost/function/detail/maybe_include.hpp>
#undef BOOST_FUNCTION_NUM_ARGS
And in 'maybe_include.hpp':
#if BOOST_FUNCTION_NUM_ARGS == 0
# ifndef BOOST_FUNCTION_0
# define BOOST_FUNCTION_0
# include <boost/function/function_template.hpp>
# endif
#elif BOOST_FUNCTION_NUM_ARGS == 1
# ifndef BOOST_FUNCTION_1
# define BOOST_FUNCTION_1
# include <boost/function/function_template.hpp>
# endif
#elif BOOST_FUNCTION_NUM_ARGS == 2
# ifndef BOOST_FUNCTION_2
# define BOOST_FUNCTION_2
# include <boost/function/function_template.hpp>
# endif
#elif BOOST_FUNCTION_NUM_ARGS == 3
# ifndef BOOST_FUNCTION_3
# define BOOST_FUNCTION_3
# include <boost/function/function_template.hpp>
# endif
#elif BOOST_FUNCTION_NUM_ARGS == 4
# ifndef BOOST_FUNCTION_4
# define BOOST_FUNCTION_4
# include <boost/function/function_template.hpp>
# endif
The list continues, handling maximum 50 arguments. To simplify, the overloading could be reduced to:
#define BOOST_FUNCTION_NUM_ARGS 0
#include <boost/function/function_template.hpp>
#undef BOOST_FUNCTION_NUM_ARGS
#define BOOST_FUNCTION_NUM_ARGS 1
#include <boost/function/function_template.hpp>
#undef BOOST_FUNCTION_NUM_ARGS
#define BOOST_FUNCTION_NUM_ARGS 2
#include <boost/function/function_template.hpp>
#undef BOOST_FUNCTION_NUM_ARGS
#define BOOST_FUNCTION_NUM_ARGS 3
#include <boost/function/function_template.hpp>
#undef BOOST_FUNCTION_NUM_ARGS
#define BOOST_FUNCTION_NUM_ARGS 4
#include <boost/function/function_template.hpp>
#undef BOOST_FUNCTION_NUM_ARGS
// etc.
The soon to come C++0x standard introduces variadic templates. I think for completeness it is necessary to mention them, although I can only report what has already been written about them. In a few words, variadic templates accept a variable number of types:
template<typename... Values> class tuple;
// also:
template<typename First, typename... Rest> class tuple;
The first template can be used with no types at all, while the second one requires at least one type. For a better understanding of how variadic templates work, here's a brief example taken from the C++0x page on Wikipedia:
void printf(const char *s)
{
while (*s)
{
if (*s == '%' && *(++s) != '%')
throw std::runtime_error("invalid format string: missing arguments");
std::cout << *s++;
}
}
template<typename T, typename... Args>
void printf(const char* s, T value, Args... args)
{
while (*s)
{
if (*s == '%' && *(++s) != '%')
{
std::cout << value;
printf(*s ? ++s : s, args...); // call even when *s == 0 to detect extra arguments
return;
}
std::cout << *s++;
}
throw std::logic_error("extra arguments provided to printf");
}
It should be noted that:
"There is no simple mechanism to iterate over the values of the variadic template. [...] With regard to function templates, the variadic parameters can be forwarded. When combined with r-value references (see below), this allows for perfect forwarding:"
template<typename TypeToConstruct> struct SharedPtrAllocator
{
template<typename ...Args> tr1::shared_ptr<TypeToConstruct> ConstructWithSharedPtr(Args&&... params)
{
return tr1::shared_ptr<TypeToConstruct>(new TypeToConstruct(std::forward<Args>(params)...));
}
}
"This unpacks the argument list into the constructor of TypeToConstruct. The std::forward<Args>(params) syntax is the syntax that perfectly forwards arguments as their proper types, even with regard to rvalue-ness, to the constructor. The unpack operator will propagate the forwarding syntax to each parameter. This particular factory function automatically wraps the allocated memory in a tr1::shared_ptr for a degree of safety with regard to memory leaks."
Variadic templates solve the overloading issue. However, the unpacking of arguments as showed until now doesn't seem to give much control. They'll probably add the possibility of singularly accessing each type. Also, the syntax of the code sample above doesn't seem very nice to me, but this is just a personal opinion.
I'm not in the standard commission and I'm not working on variadic templates nor on rvalue references, so I won't discuss them further. The approach with normal templates has already been explored. Thus, the reader will excuse me if I use a totally different approach, since we're still in a theoretical context. The truth is that I thought about my system before hearing about variadic templates and as long as I don't know how to access each type singularly, I can only use my system to implement variable argument list delegates. There will always be time for implementing delegates with variadic templates.
In Dynamic C++ delegates for methods of dynamic classes are possible and they're also type-safe without having to use templates. I took some inspiration from C# delegates, especially regarding the syntax and behavior of multicast delegates. I thought of two types of delegates. The one is a standard type and the second one is a variable argument list delegate. The latter one will be used to implement signals later on.
A standard delegate can be used this way:
#include <dynamic>
int f()
{
// declare the delegate
DYN_DELEGATE(int, method_delegate, (int x, int y));
simple s;
method_delegate += DYN_CLASS_METHOD(&s, typeid(simple::max(int, int)));
return method_delegate(10, 20);
}
The presence of argument names (x and y) is optional. The += and -= operators are overloaded to provide a syntax similar to C# delegates. And here an example of a multicast delegate:
void f()
{
// declare delegate
DYN_DELEGATE(char *, method_delegate, (char *));
string_converter_1 c1;
method_delegate += DYN_CLASS_METHOD(&c1, typeid(string_converter_1::upper(char *)));
string_converter_2 c2;
method_delegate += DYN_CLASS_METHOD(&c2, typeid(string_converter_2::reverse(char *)));
char str[] = "hello";
// prints "OLLEH"
cout << method_delegate(str);
}
The delegates could be of the same class, but in this sample I wanted to emphasize the fact that delegates can be of multiple classes (even of different types). When several delegates are combined, the functor returns the return value of the last invoked delegate.
My implementation is based on functors:
class delegate
{
public:
delegate() {};
protected:
// implemented natively:
// void invoke(const typeinfo & ti, ...);
void add(const method & m);
};
#define DYN_DELEGATE(t, f, p) \
dynamic class f##_delegate : public delegate { \
public: \
f##_delegate () {}; \
NAKED t operator() p { \
void *p = (void *) this; \
type_info ti = typeid(); \
__asm { \
lea edx, ti \
push edx \
mov ecx, p \
call invoke \
} \
invoke(); }; \
} f ;
The operator() overload should be declared as naked and use
inline assembly in order to avoid to explicitly return a type. I'm perfectly
conscious that Visual C++ dropped asm inline support for 64-bit platforms, but guess
what? I don't like that. C++ must have asm inline capabilities. The stack is
cleared by the invoke method which is implemented natively. As you can see,
this mechanism is very lightweight, since for each delegate only the code inside
the derived class is being re-generated: just a few opcodes. The code inside the
delegate class is generic and is shared by all derived classes. It
should be noted that I used the "this calling convention" to call the invoke
method with inlined assembly: this, of course, is compiler specific.
The invoke method knows all it needs to know about the stack thanks to the
information contained in the type_info class. To avoid parsing the signature
of the method, explicit stack information could be provided. Of course, this
internal information would be platform and compiler specific. When the delegate
is used to invoke only one method, the stack is cleared by the invoked method itself
if it follows the stdcall calling convention and by the invoke method in case
the compiler uses the "cdecl calling convention" for class methods. In case the
delegate is used to invoke more than one method, the invoke method also needs
to redispose the arguments on the stack for each method it calls. On x86 a
simple "add esp" instruction followed by a memcpy on the stack would be
enough to copy the arguments, while on other platforms which use a fast call
syntax (this means using registers and not the stack to pass arguments) some
push and pop operations are necessary in order to save the data and restore
it later.
The second type of delegate is able to invoke methods with less arguments than the functor itself:
void f(dynamic *obj, int param1, int param2)
{
// declare variable argument list delegate
DYN_DELEGATE_VA(void, method_delegate, (int, int));
method_delegate += DYN_CLASS_METHOD(obj, SIGNATURE(void notify1(int, int)));
method_delegate += DYN_CLASS_METHOD(obj, SIGNATURE(void notify2(int)));
method_delegate(param1, param2);
}
The SIGNATURE macro only provides a more esthetical way to specify a
string, just like the SIGNAL and SLOT macros in the Qt framwork do. As
usual, the stack operations are performed thanks to the information contained in
the type_info class, although rather than letting the type_info constructor
parse the signature of the method in order to provide stack information, it
would be better to give the type_info pointer to the obj and letting it so
retrieve the stack information from the metadata of the dynamic object.
Variable argument list delegates are a very powerful tool as we'll later see.
For the same reason explained in the past paragraph, generic function pointers are
possible for methods of dynamic classes. This isn't true in normal C++, as
multiple inheritance sometimes requires that the this pointer is adjusted and
thus all function pointers operation on method of static classes need to be
typed. In Dynamic C++ this code is possible:
void (dynamic::*pstrcat)(char *) = NULL;
// my_string is a dynamic class
dynamic *obj = new my_string();
pstrlen = &my_string::cat;
(obj->*pstrcat)("hello");
If my_string was an external object, then the method pointer would be
retrieved dynamically through the name of the method combined with the signature
of the function pointer (the signature is built by the compiler). If the method pointer can't be retrieved dynamically,
an exception is thrown.
The this pointer is adjusted dynamically by finding the class in the tree
hierarchy which references the method also referenced by the function pointer.
This is the shortest paragraph of the entire article. Dynamic structures are just like static structures: identical to their class counterpart except for the default scope, which for structures is public, while for classes it's private.
Nothing else to mention. Everything said for dynamic classes applies to dynamic structures.
void dyncall(dynamic & obj)
{
obj.method();
}
When calling this method, it doesn't matter whether the object passed is a structure or a class.
Dynamic enumerators are necessary to export values associated to names and also to expose these names to scripting languages. Even the Qt framework inserts enumerators in its metadata when required.
Dynamic enumerators are used just like static ones and locally behave the same way, but they are also dynamic classes. Here's a small sample which enumerates the names inside an enumerator:
dynamic enum hello
{
a,
b,
c
};
void f()
{
int num = dyn::get_members_number(typeid(hello));
for (int x = 0; x < num; x++)
{
cout << dyn::get_member(typeid(hello), x).name() << endl;
}
}
Clearly get_member returns a type_info class. The value of
a member can
be retrieved (if available) by index or number:
val = dyn::get_member_value(typeid(hello), x);
// or
val = dyn::get_member_value(typeid(hello), "b");
Only the values of static members can be retrieved by specifing only the
type_info, of course. It should be
noted that a syntax like the following would be nicer:
val = hello::get("b");
However, to introduce this kind of syntax without generating the same methods for every enumerator (being static functions they have no access to the class itself), dynamic enumerators would have to be treated as special objects. The implementation seen earlier, while not being as nice, treats dynamic enumerators as every other dynamic object. In fact, the same library functions to enumerate members of enumerators can be used for dynamic classes and also for dynamic namespaces, as we'll see in the next paragraph. Obviously, the compiler treats enumerators from the syntax point of view in a different way, I'm only talking about the low level implementation.
Dynamic namespaces are similar to dynamic numerator in the way they are implemented and have two effects:
This means that simple is a dynamic class and not a static one:
dynamic namespace hello
{
class simple
{
// ...
};
}
To make a static class out of simple inside a dynamic namespace, it is
necessary to use the static keyword:
dynamic namespace hello
{
static class simple
{
// ...
};
}
The global namespace is by default static, but that can be changed from the compiler settings. When the global namespace is dynamic all other namespace declared are by default dynamic and static only when declared that way:
static namespace hello
Just like objects, dynamic namespaces can be imported from external modules:
extern dynamic namespace hello;
And just like all dynamic objects the members of dynamic namespaces can be enumerated:
void f()
{
int members = dyn::get_members_number(typeid(hello));
for (int x = 0; x < members; x++)
{
type_info ti = dyn::get_member(typeid(hello), x);
if (ti.ptype() == primitive_type_class)
{
dynamic *obj = new ti;
unsigned int version = obj-><unsigned int>version();
delete obj;
}
}
}
This code calls the version method of every class contained in the hello
namespace. Not very useful, but it's only an example. As we'll see later the
capability of dynamically enumerating all members in a namespace is very useful.
The following subparagraphs show how Dynamic C++ can be used to replicate known framework models. Actually, there are many more possibilities, but it isn't the scope of this paper to list them all. Instead, I will focus on two popular framework models: signals & slots and events.
My implementation of signals is a mixture of functors (like those used by the Boost library) and Qt signals. It isn't possible to implement Qt signals without the moc, because they are declared like normal methods but their code is generated by the moc:
// SIGNAL 0
void Counter::valueChanged(int _t1)
{
void *_a[] = { 0, const_cast<void*>(reinterpret_cast<const void>(&_t1)) };
QMetaObject::activate(this, &staticMetaObject, 0, _a);
}
Generating at compile time the code of a method isn't a C++ feature. Thus, to implement signals, a different system has to be used.
dynamic class MyWidget : public FXWidget
{
public:
MyWidget();
signals:
SIGNAL(valueChanged, (int));
};
dynamic class MyClass
{
public:
MyClass();
private:
MyWidget widget;
slots:
void onValueChanged(int);
}
MyClass::MyClass()
{
widget.valueChanged.connect(this, SLOT(onValueChanged(int));
// or
widget.connect(SIGNAL(valueChanged(int)), this, SLOT(onValueChanged(int));
// or
connect(&widget, SIGNAL(valueChanged(int)), this, SLOT(onValueChanged(int));
}
It is rather obvious that I used variable argument list delegates in my
implementation. The first connect method is called directly from the functor,
while the second connect method is called dynamically by giving only the
signature of the signal. The third connect is identical to the Qt one. The
second and third way of calling connect has to be
provided for dynamic connections between signals and slots, which is, for
instance, very useful when one wants to expose this functionality to a
scripting language. Emitting a signal can be done the same way as in the Qt
framework:
emit valueChanged(value);
Signals under my implementation cannot be overloaded. This one flaw is mitigated by the fact that by using variable argument list delegates a signal can be connected to a slot with less types (just as in the Qt framework):
connect(&widget, SIGNAL(valueChanged(int)), this, SLOT(onValueChanged());
If the Qt framework had to be implemented using Dynamic C++, it could use the moc to generate only the methods of its signals (this is if it wanted to mantain its signals implementation). You could ask where the advantage of dynamic classes stands if the moc has to be used anyway. Remember the Fragile Base Class problem? The Qt framework would get rid of that problem by using dynamic classes, making the deployment of the runtime very easy.
And here a small example of an event driven framework. The syntax is about the same used in the .NET framework:
dynamic class MyForm : public FXForm
{
public:
MyForm();
private:
FXButton *button;
};
MyForm::MyForm()
{
button = new FXButton(this);
button.click += EventHandler(this, HANDLER(onClicked));
}
The signature of the event handler can be built by the functor from its own signature. It is also possible that all events in the framework have the same type of arguments. This is an implementation choice.
I don't think there's anything to add, also because the implementation of events doesn't differ very much from that of standard delegates.
Of course, being a natively compiled language, C++ can't generate other C++ code at runtime. Reflection in a C++ context can only rely on external scripting languages integrated into the C++ project. However, given the capabilities of dynamic objects to expose themselves, it is also very easy to expose them to a scripting language.
The most popular choices regarding embeddable scripting languages are Python and Lua. In C++ projects the most common way to expose objects to Python is by using either Boost.Python or SWIG.
But there is another way, which was cleverly demonstrated by Florian Link
with his PythonQt (not to confuse
with PyQt, which operates on the same principle as SWIG does). PythonQt exploits
the functionality of QMetaObject in order to create a generic exposer for
QObject derived classes to Python. It automatically handles all native data
types and all QVariant derived types such as QString. Here's the list of
features and missing things taken directly from the homepage:
Features
* Access all slots, properties, children and registered enums of any QObject
derived class from Python
* Connecting Qt Signals to Python functions (both from within Python and from
C++)
* Wrapping of C++ objects (which are not derived from QObject) via
PythonQtCPPWrapperFactory
* Extending C++ and QObject derived classes with additional slots, static
methods and constructors (see Decorators)
* StdOut/Err redirection to Qt signals instead of cout
* Interface for creating your own import replacement, so that Python scripts can
be e.g. signed/verified before they are executed (PythonQtImportInterface)
* Mapping of plain-old-datatypes and ALL QVariant types to and from Python
* Support for wrapping of user QVariant types which are registerd via QMetaType
* Support for Qt namespace (with all enumerators)
* All PythonQt wrapped objects support the dir() statement, so that you can see
easily which attributes a QObject, CPP object or QVariant has
* No preprocessing/wrapping tool needs to be started, PythonQt can script any
QObject without prior knowledge about it (except for the MetaObject information
from the moc)
Non-Features
Features that PythonQt does NOT support (and will not support):
* you can not derive from QObjects inside of Python, this would require wrapper
generation like PyQt does
* you can only script QObject derived classes, for normal C++ classes you need
to create a PythonQtCPPWrapperFactory and adequate wrapper classes or add
decorator slots
* you can not access normal member functions of QObjects, only slots and
properties, because the moc does not store normal member functions in the
MetaObject system
Among the non-features the only one which would affect Dynamic C++ if the same mechanism was applied is the inheritance related one. In order to let a Python class derive from a C++ class, it is necessary to write a wrapper C++ class in order to correctly solve the virtual methods. Just to give the idea:
class A
{
public:
A();
virtual void method();
};
class A_wrapper
{
public:
A_wrapper();
virtual void method()
{
// has been overwritten by the derived python class?
if (overwritten)
call_py_method();
else
call_A_method();
}
};
However, many times inheritance is not what the programmer needs, in some cases exposing the C++ object to Python is more than enough. In that case, a generic runtime wrapper for C++ objects like PythonQt is the best choice. Just consider how easy it is to explose a class from PythonQt:
PythonQt::self()->registerClass(&QPushButton::staticMetaObject);
And access it then from Python code:
from PythonQt import *
# call our new QPushButton constructor
button = QPushButton("sometext");
# call the move slot (overload1)
button.move(QPoint(0,0))
# call the move slot (overload2)
button.move(0,0)
I invite everyone to download the sources of PythonQt and see how this mechanism is easy yet powerful. The same could be applied even better to Dynamic C++. The one low point of PythonQt is that it can call only slots, because the Qt moc generates metadata only for slots and signals (and in Qt classes not all methods are slots as well). In Dynamic C++ all public methods (and members) could be exposed to a scripting language. Moreover, the presence of dynamic namespaces makes it possible to expose a whole namespace (meaning all the elements it contains) at once with just one line of code. If the idea is appreciated, a method to simplify the task of wrapping a class to implement inheritance capabilities could be provided and used in conjunction with the generic exposer.
Dynamic C++ brings some advanced implications which aren't part of the proposal itself, but are worth mentioning.
In the context of C++ the term 'metaprogramming' is ambigous. I don't mean template metaprogramming. I mean the ability to add or replace the methods of a class at runtime. Although I'm not a Ruby admirer, this language provides an easy metaprogramming system:
# re-open Ruby's Time class
class Time
def yesterday
self - 86400
end
end
today = Time.now # => Thu Aug 14 16:51:50 +1200 2008
yesterday = today.yesterday # => Wed Aug 13 16:51:50 +1200 2008
Time is an environment class and the method yesterday is being added
to it at
runtime. This code could be rewritten in its Dynamic C++ equivalent:
#include <dynamic>
extern dynamic class Time;
// external virtual metnod
// (can be applied only to dynamic classes)
virtual Date Yesterday()
{
return (this.Now() - 86400);
}
// main code
void f()
{
// adds the method if there isn't one with the same signature
dyn::modify_method(typeid(Time), typeid(Yesterday));
Time t;
cout << t.Now() << endl;
cout << t.Yesterday() << endl;
}
Yesterday is an external virtual method, a new thing, its first implicit
argument is a this pointer, of course. External virtual methods access the
members or methods of their assigned object dynamically.
The organization of the metadata of a dynamic object has to be slightly modified in order to allow metaprogramming, but nothing complicated. This feature is totally possible in Dynamic C++, technically speaking. What has to be decided is whether metaprogramming is a valid paradigm for C++ or not. I have no opinion about this, but I felt it was worth mentioning the possibility.
By managed bindings I mean the possibility for Dynamic C++ to interact with objects of managed frameworks like .NET or Java . While Dynamic C++ makes it possible to expose its objects to scripting languages, it can also expose them to managed frameworks. Moreover, it is also possible to expose managed framework objects to Dynamic C++, thanks to the absence of the FBC problem and the flexible layout of dynamic objects.
Here's a piece of C# code taken from the MSDN:
using System;
using System.Security.Cryptography;
using System.Text;
class RSACSPSample
{
static void Main()
{
try
{
//Create a UnicodeEncoder to convert between byte array and string.
UnicodeEncoding ByteConverter = new UnicodeEncoding();
//Create byte arrays to hold original, encrypted, and decrypted data.
byte[] dataToEncrypt = ByteConverter.GetBytes("Data to Encrypt");
byte[] encryptedData;
byte[] decryptedData;
//Create a new instance of RSACryptoServiceProvider to generate
//public and private key data.
RSACryptoServiceProvider RSA = new RSACryptoServiceProvider();
//Pass the data to ENCRYPT, the public key information
//(using RSACryptoServiceProvider.ExportParameters(false),
//and a boolean flag specifying no OAEP padding.
encryptedData = RSAEncrypt(dataToEncrypt,RSA.ExportParameters(false), false);
//Pass the data to DECRYPT, the private key information
//(using RSACryptoServiceProvider.ExportParameters(true),
//and a boolean flag specifying no OAEP padding.
decryptedData = RSADecrypt(encryptedData,RSA.ExportParameters(true), false);
//Display the decrypted plaintext to the console.
Console.WriteLine("Decrypted plaintext: {0}",
ByteConverter.GetString(decryptedData));
}
catch(ArgumentNullException)
{
//Catch this exception in case the encryption did
//not succeed.
Console.WriteLine("Encryption failed.");
}
}
// etc.
}
This could be rewritten in Dynamic C++:
#include <DotNET>
using namespace System;
using namespace System::Security::Cryptography;
using namespace System::Text;
void main()
{
UnicodeEncoding ByteConverter;
NETArray<byte> dataToEncrypt = ByteConverter.GetBytes(_T("Data to Encrypt"));
NETArray<byte> encryptedData;
NETArray<byte> decryptedData;
RSACryptoServiceProvider RSA;
encryptedData = RSAEncrypt(dataToEncrypt, RSA.ExportParameters(false), false);
decryptedData = RSADecrypt(encryptedData, RSA.ExportParameters(true), false);
Console::WriteLine("Decrypted plaintext: {0}",
ByteConverter.GetString(decryptedData));
}
The objects in the code sample are .NET objects wrapped into Dynamic C++ objects. The marshalling of types is very easy, thanks to the metadata of Dynamic C++. When a dynamic C++ wrapper object is destroyed, its destructor deferences the .NET object, so that the job of actually disposing the .NET object is left to the garbage collector.
Framework bindings require a good amount of work, but they can be implemented.
Dynamic C++ is an extension to normal C++, not a radical change. To better explain what I mean by that, consider functions versus objects. C++ is a multiparadigm language and doesn't force either of them upon the developer. Similarly, Dynamic C++ doesn't force dynamism. Static constructs have their advantages over dynamic constructs and viceversa. I spent the whole paper enumerating the features of dynamic constructs. Thus, it is not necessary to repeat them here. Instead, I'll briefly list the advantages of staticity, in order to make clear why it is so important to let the developer decide.
First off, static objects are most of the times faster than dynamic ones. Not only, they're also less memory expensive. Thus, static constructs can be considered lightweight when compared to their dynamic counterparts. Just consider a dynamic enumerator compared to a static one. Static enumerators exist only in the C++ syntax, they have no impact on the final size of the code. Meanwhile, a dynamic enumerator is an object with all its static metadata.
The second advantage of static constructs is that they are internal. Apart from the RTTI, no metadata is generated for static constructs. Although dynamic objects have the ability to explicitly control what will end up in the metadata and what won't, they are much easier to reverse engineer than static objects. I warned exhaustively about the dangers of unwanted metadata in my article about .NET Internals & Native Compiling. Anyone who desires to investigate the subject can read that paper. By letting the developer decide what is metadata and what isn't, Dynamic C++ avoids the problems of a technology which forces dynamism at all costs. In this regard, I think that Dynamic C++ doesn't violate the way C++ was thought, but extends its multiparadigm implementation.
I'm perfectly aware that the dynamism adds yet another layer of complexity to C++, but I don't see another way to increase its capabilities. One might reconsider the inheritance between dynamic and static objects. This feature could be removed for the sake of simplicity. I believe that the evolution of technologies relies in improving existing ones and not by adopting others. Moreover, although dynamism adds complexity, on the other hand it simplifies many tasks and helps avoiding ugly C++ hacks, which can make the code very hard to understand.
I know that this might be the most useless paper I have ever written. But, as I don't get paid for what I write, I tend to write about things I care about or I am interested in without thinking too much about the feedback. I'm fully aware that if I had written a detailed paper about the on disk structure of NTFS instead, it would have helped many people writing their own applications. But divulgation isn't everything. I don't expect that this paper should be accepted as it is, but I'd like to see the beginning of a debate about the future of the C++ language. Modifying the C++ language can't be a one man's effort, that's why I wrote this proposal. I'm of the idea that C++ can evolve and have all the strengths newer languages have, mantaining its low level capabilities.
Daniel Pistelli